توضیحات
پروژه دسته بندی حملات سیستم تشخیص نفوذ(IDS) با تکنیک های مختلف یادگیری ماشین در نرم افزار پایتون(Jupyter Notebook)
امنیت شبکه در رایانش ابری:
رایانش ابری یکی از فناوری های نوین در دنیای IT است؛ علىرغم نوین بودن این فناوری، همچنان ساختارهای سنتی IT در این فناوری وجود دارند و روش فعالیت اجزای این ساختارها، همچنان مبتنی بر استانداردهایی است که تاکنون در دنیای IT استفاده شده اند. عمده ترین تفاوت، وجود شیوه مدیریتی جدید و نحوه توزیع و تخصیص منابع است. یکی از اصلی ترین اجزای ساختارهای IT بستر شبکه های کامپیوتری است. کلیه ارتباطات، کنترل ها و انتقال داده ها از طریق بستر شبکه امکان پذیر است. رایانش ابری هم به عنوان یک عضو از خانواده IT، از این جزء استفاده می کند. حملاتی که از داخل ابر یا خارج از آن، قصد آسیب رساندن و سوء استفاده از منابع و اطلاعات ابر را دارند، از طریق شبکه خود را به مقصد مورد نظر می رسانند؛ یاحتی با از کار انداختن شبکه، کل ابر را از کار می اندازند. بنابراین با ایمن کردن بستر شبکه و تشخیص و برخورد با حمله ها در همان ابتدای ورود به بستر شبکه، می توان در فعالیت حمله ها اختلال ایجاد کرد یا راه نفوذ آنها را بست. بنابراین با کنترل کردن ارتباطات و فعالیت های آنها بر روی بستر شبکه، می توان از نوع های خاصی از حمله ها جلوگیری کرد. در صورت ایمن نبودن محیط شبکه و نبود نظارت بر عملکرد ارتباطات مختلف بر روی شبکه، نمی توان بر روی نگرانی های امنیتی مطرح شده در بخش ۱-۲، کنترل داشت و ابر آسیب خواهد دید.
سیستم های تشخیص نفوذ(Intrusion detection system):
یک سیستم تشخیص نفوذ، نرم افزاری است که به صورت خودکار، توانایی شناسایی رفتارهای پرخطر و نفوذهای غیر مجاز به یک سیستم IT را دارد. سیستم جلوگیری از نفوذ، توانایی پاسخ دادن به نفوذ شناسایی شده توسط قسمت تشخیص نفوذ را دارد و از راه هایی مانند تغییر محتوای حمله، تغییر محیط امنیتی، تغییر پیکربندی کنترل های امنیتی، تغییر تنظیمات تجهیزات شبکه، مسدود کردن ارتباط برنامه حمله کننده و روش های بسیار دیگری مانع از رسیدن فرآیند نفوذ کننده به اهداف خود می شود. قرارگیری یک سیستم تشخیص نفوذ و یک سیستم جلوگیری از نفوذ در کنار هم یا ترکیب کردن این سیستم ها با همدیگر، یک سیستم تشخیص و جلوگیری از نفوذ را ایجاد می کند. حمله هایی که به یک سیستم وارد می شوند، دو نوع هستند. نوع اول، حمله هایی هستند که توسط عوامل خارج از سیستم به آن وارد می شوند و نوع دوم، حمله هایی است که توسط عوامل داخلی انجام می شوند. در واقع حمله های نوع دوم، تلاش کاربرهای داخلی سیستم، برای دسترسی غیرمجاز به بعضی از امکانات سیستم است.
عملکرد معمول یک سیستم تشخیص نفوذ:
هرکدام از جزءها و نهادهای یک سیستم IT، سیستم نظارتی خاص خود را دارند و می توانند مستقل یا با همکاری سایر بخش های نظارتی فعالیت کنند. شکل زیر حالت معمول یک سیستم تشخیص و جلوگیری از نفوذ را نشان می دهد. در حالت معمول، روند فعالیت یک سیستم تشخیص و جلوگیری از نفوذ به این شکل است که :
1- ابتدا وضعیت و داده های مربوط به آن جزء خاص از سیستم، به وسیله نرم افزارها و سخت افزارهای کنترلی، جمع آوری می شود.
۲- داده های کنترلی جمع آوری شده به بخش تحلیل و تشخیص داده می شوند. بخش تحلیل و تشخیص، داده های جمع آوری شده در مرحله اول را با اطلاعات موجود در پایگاه دانش مقایسه و بر اساس مجموعه اطلاعاتی که بدست می آورد تصمیم می گیرد که آیا حمله ای اتفاق افتاده است یا نه، و اگر حمله ای اتفاق افتاده است بر اساس نوع حمله، اطلاعات لازم را به مرحله بعد می فرستد.
۳- در این مرحله، اطلاعات مربوط به وجود یا عدم وجود حمله، از طرف بخش تحلیل و تشخیص دریافت شده است. بر اساس اطلاعات دریافتی، بخش هشداردهی، هشدار و وضعیت مربوطه را به بخش پاسخ دهی اعلام می کند.

شکل روند معمول فعالیت سیستم های تشخیص و جلوگیری از نفوذ.
4-در بخش پاسخ دهی، وضعیت و اطلاعات دریافتی از بخش قبل بررسی و عمل لازم در صورت وجود حمله، صورت می گیرد. در حالت سنتی، معمولا توسط یک شخص که در زمینه امنیت خبره است و با پیکربندی شبکه در سیستم آشنا است، پاسخ مناسب تولید می شود.
5-پاسخی که از طرف بخش پاسخ دهی دریافت شده است، به سیستم اعمال می شود و همزمان به عنوان اطلاعات جدیدی به پایگاه دانش اضافه می شود یا اطلاعات پایگاه دانش را تغییر می دهد تا در تحلیل های بعدی استفاده شود.
محیط های مورد نظارت توسط سیستم تشخیص نفوذ:
سیستم های تشخیص نفوذ می تواند برای انجام کار خود محیط های مختلفی را مورد نظارت قرار دهد که شامل شامل موارد زیر هستند که حتی می توان از ترکیب کردن این محیطها با همدیگر هم برای نظارت استفاده کرد.
١- مبتنی بر شبکه(network-based): جریان و ترافیک داده ها در بخش های مختلف شبکه و تجهیزات آن را مورد نظارت قرار می دهد و فعالیت های پروتکل های کاربردی و شبکه را مورد تحلیل قرار می دهد و داده هایی را از آنها جمع آوری می کند.
2- مبتنی بر میزبان(host-based): نظارت بر همه یا بخشی از قسمت های رفتارها و حالت های سیستم کامپیوتری. در این رویکرد، اینکه چه برنامه ها یا فرآیندهایی به چه منابعی دسترسی داشته اند مورد بررسی قرار می گیرند.
3-مبتنی بر کاربرد(protocol-based): بر روی رخدادهایی که از طریق یک برنامه خاص انجام می گیرند تمرکز می شود و فایل های عملکرد آنها، کارایی آنها و میزان استفاده از آنها مورد تحلیل قرار می گیرند.
روش های مختلف کشف نفوذ در سیستم تشخیص نفوذ:
روش های شناخته شده و سنتی برای تشخیص و تشخیص نفوذ، در سه کلاس مختلف قرار می گیرند:
١- تشخیص سوء استفاده(misuse detection): در این روش، الگوهای ویژه شناخته شده از رفتارهای غیر مجاز که اصطلاحاً امضاها نامیده می شوند، برای پیش بینی و تشخیص تلاش های مخرب مشابه استفاده می شوند.
2-تشخیص ناهنجاری(anomaly detection): برای شناسایی رفتارهای ناهنجار و نامعمول استفاده می شود. سیستم تشخیص نفوذ از تعدادی الگوی صحیح رفتاری تشکیل شده است و هر رفتاری که با این الگوها مطابقت نداشته باشد، یک نفوذ یا رفتار خطرناک تلقی می شود.
۳- ترکیبی: این روش بر اساس ترکیب روش های تشخیص سوء استفاده و تشخیص ناهنجاری عمل می کند. درواقع ایده اصلی این روش، تشخیص حمله های شناخته شده توسط روش تشخیص سوء استفاده و تشخیص حملات ناشناخته به وسیله روش تشخیص ناهنجاری است. سه روشی که در بالا معرفی شدند، روش های سنتی و معمول در سیستم های تشخیص نفوذ هستند. امروزه علم هوش مصنوعی با پیشرفت های خود توانسته است که به عنوان یک راه حل برای مسائل سخت و دشوار، به حوزه های علمی دیگر نیز وارد شود. استفاده از روش های هوش مصنوعی به منظور تشخیص نفوذ در سیستم تشخیص نفوذها، در حال گسترش است. استفاده از روش های یادگیری ماشین و پردازش تکاملی توانسته اند، در بهبود عملکرد تشخیص نفوذها مؤثر باشند.
ویژگی های یک سیستم تشخیص نفوذ مناسب:
تعدادی از ویژگی های لازم برای یک سیستم تشخیص نفوذ مطلوب در زیر آورده شده است :
1- وظایف خود را با کمترین دخالت انسان انجام دهد.
۲- تحمل پذیری در مقابل نقص، ادامه حیات و قابلیت ترمیم نقص ها را داشته باشد.
٣- برای یک شبکه خاص، به راحتی طراحی و راه اندازی شود.
۴- با تغییر رفتار کاربرها و سیستم اصلی، در طول زمان خود را وفق دهد.
۵- بلادرنگ عمل کند.
۶- بتواند اکثر نفوذها را با کمترین نرخ تشخیص اشتباه، تشخیص دهد.
۷- بتواند بر روی خود هم نظارت کند و از خود در مقابل حمله ها محافظت کند.
۸- زمانی که سیاست های امنیتی تغییر داده می شوند، بتواند پیکربندی و تنظیمات خود را به روز کند.
9- با کمترین هزینه و سربار، همگام با فعالیت سیستم نظارت شونده، فعالیت کند.
همگام با رشد شبکه های کامپیوتری، حملات و نفوذها به این شبکه ها نیز گسترش یافته و به شکل های متعددی صورت می پذیرد. نفوذ مجموعه اقدامات غیرقانونی است که صحت، محرمانگی و یا دسترسی به یک منبع را به خطر می اندازد. نفوذگرها را می توان به دو دسته نفوذگرهای خارجی و نفوذی های داخلی دسته بندی کرد. نفوذگرهای خارجی کسانی هستند که اجازه استفاده از سیستم را ندارند اما سعی می کنند سیستم را مورد دسترسی قرار دهند و نفوذگرهای داخلی کسانی هستند که برای دستیابی به سیستم اختیارات محدودی دارند، اما سعی می کنند به منابعی که اجازه استفاده از آنها راندارند، دسترسی پیدا کنند. نفوذ با انگیزه های متفاوت سیاسی، مالی، نظامی و حتی نشان دادن مهارت با توجه به نقاط ضعف موجود در برنامه های کاربردی و عیوب نرم افزاری ضعف طراحی پروتکل و طراحی سیستم عامل در طی مراحل شناسایی، یافتن نقاط ضعف و بدست آوردن سناریوی نفوذ از جانب نفوذی صورت می گیرد. به منظور مقابله با نفوذکنندگان به سیستم ها و شبکه های کامپیوتری روش متعددی تدوین شده است که روش های تشخیص نفوذ با داده کاوی نامیده می شود. هدف از تشخیص نفوذ با داده کاوی این است که، استفاده غیرمجاز سوء استفاده و آسیب رساندن به سیستم ها و شبکه های کامپیوتری توسط هر دو دسته کاربران داخلی و حمله کنندگان خارجی شناسایی شود. به طور کلی روش های تشخیص نفوذ داده کاوی به دو دسته اصلی تشخیص سوءاستفاده و تشخیص رفتار غیرعادی تقسیم می شوند. در روش تشخیص سوء استفاده از الگوهای نفوذ شناخته شده برای شناسائی نفوذها استفاده می شود. در حالیکه در روش های تشخیص رفتار غیر عادی،رفتار عادی کاربران ملاک عمل قرار داده می شود و در نتیجه هر گونه رفتار مغایر با آن به عنوان تلاش جهت نفوذ به سیستم شناسائی می گردد.
سیستم های تشخیص نفوذ داده کاوی اولیه با تحلیل فایل رخدادها که توسط سیستم عامل و برنامه های کاربردی ایجاد می شوند، کار می کردند. اما به مرور که شبکه ها پیچیده شدند به داده های کافی برای شناسائی قاطعانه یک حمله دسترسی نداشتند. بنابراین توجه به روش های تشخیص نفوذ پیچیده تر مبتنی بر تحلیل داده های شبکه یا میزبان، معطوف شد. بر اساس منبع اطلاعات دریافتی، سیستم های تشخیص نفوذ داده کاوی تشخیص نفوذ با استفاده از تکنیک های… به سه دسته، مبتنی بر شبکه و مبتنی بر میزبان و توزیع شده تقسیم می شوند. نفوذی ها معمولاً از عیوب نرم افزاری، شکستن کلمات رمز، استراق سمع ترافیک شبکه و نقاط ضعف طراحی برای نفوذ به سیستم و شبکه های کامپیوتری استفاده می کنند. اغلب لازم است با کشف هر حمله جدید سیستم تشخیص نفوذ داده کاوی بروز رسانده شود. سازندگان این سیستم، ابتدا سناریوهای حمله و نقاط ضعف سیستم را تحلیل و طبقه بندی می کنند، سپس قوانین و الگوهای مناسبی را برای تشخص این سوء استفادهها به طور دستی کد می کنند. به دلیل ماهیت دستی و غیر الگوریتمی فرآیند توسعه در سیستم های تشخیص نفوذ داده کاوی، اعمال تغییرات در آنها کند و پر هزینه است. سیستم های تشخیص نفوذ به صورت سیستم های نرم افزاری و سخت افزاری ایجاد شده و هر کدام مزایا و معایب خاص خود را دارند.
به طور کلی سه عملکرد اصلی سیستم تشخیص نفوذ عبارتند از:
-نظارت و ارزیابی
-کشف
-واکنش.
در دنیای امروز، کامپیوتر و شبکه های کامپیوتری متصل به اینترنت نقش عمده ای در ارتباطات و انتقال اطلاعات ایفا می کند. در این بین افراد سودجو با دسترسی به اطلاعات مهم مراکز خاص یا اطلاعات افراد دیگر و با قصد اعمال نفوذ یا اعمال فشار و یا حتی به هم ریختن نظم سیستمها، به سیستم های کامپیوتری حمله می کنند. بنابراین لزوم حفظ امنیت اطلاعاتی و حفظ کارآیی در شبکه های کامپیوتری که با دنیای خارج ارتباط دارند، کاملا محسوس است.
تشخیص نفوذ عبارت است از تشخیص تلاش هایی که جهت دسترسی غیرمجاز به یک شبکه یا کاهش کارآیی آن انجام می شوند. در تشخیص نفوذ باید ابتدا درک صحیحی از چگونگی انجام حملات پیدا کرد. سپس بنابر درک بدست آمده روشی دو مرحله ای را برای متوقف کردن حملات برگزید. اول اینکه مطمئن شوید که الگوی عمومی فعالیت های خطرناک تشخیص داده شده است. دوم اینکه اطمینان حاصل کنید که با حوادث مشخصی که در طبقه بندی مشترک حملات نمی گنجند، به سرعت رفتار می شود. به همین دلیل است که بیشتر سیستم های تشخیص نفوذ بر مکانیزم هایی جهت بروزرسانی نرم افزارشان متکی هستند که جهت جلوگیری از تهدیدات شبکه به اندازه کافی سریع هستند. البته تشخیص نفوذ به تنهایی کافی نیست و باید مسیر حمله را تا هکر دنبال کرد تا بتوان به شیوه مناسبی با وی نیز برخورد کرد.
امروزه از سیستم های تشخیص نفوذ به عنوان یکی از مهم ترین سیستم ها در تشخیص حملات و ارتقاء امنیت شبکه ها استفاده می شود. معمولاً این سیستم ها با مجموعه داده های حجیم و تعداد ویژگی های زیاد روبرو هستند. از این رو، انتخاب ویژگی های مناسب می تواند راه کار مناسبی برای بهبود عملکرد آنها در تشخیص حملات باشد. از طرف دیگر، ظهور و بروز حملات جدید در شبکه های کامپیوتری با توجه به کشف مستمر آسیب پذیری های جدید یک مشکل اجتناب ناپذیر است. برای مقابله با این مسأله، سیستم های تشخیص نفوذ با استفاده از تکنیک های داده کاوی این کار را انجام می دهند.
داده کاوی(Data Mining):
تکنولوژی های جدید اطلاعاتی و ارتباطی، و همچنین فناوری های پشتیبان تصمیم، با جمع آوری، ذخیره، ارزیابی، تفسیر و تحلیل، بازیابی و اشاعه اطلاعات به کاربران خاص، می توانند در اطلاع یابی به موقع، صحیح و مورد نیاز به افراد تاثیر بسیار زیادی داشته باشند. یکی از ابزار های مورد استفاده در این فناوری ها، داده کاوی می باشد.
داده کاوی شامل استفاده از ابزار های پیشرفته تحلیل داده به منظور کشف الگوهای معتبر و روابط در مجموعه داده های بزرگ است. این ابزار ها، مدل های آماری، الگوریتم های ریاضی و روشهای یادگیری ماشین می باشد. داده کاوی فراتر از جمع آوری و مدیریت داده است و شامل تجزیه و تحلیل و پیشگویی می شود. نام دیگر آن کشف دانش در پایگاه داده است. به صورت ساده اینطور میتوان بیان کرد که داده کاوی به استخراج دانش از حجم انبوهی از داده ها اطلاق می شود.
داده کاوی شامل مجموعه ای از تکنیک هایی است که در حوزه های دیگر علمی مانند پایگاه داده، آمار، یادگیری ماشین، شبکه های عصبی، بازیابی اطلاعات و تشخیص الگو می توان آن را یافت. تکنیک های متنوعی در داده کاوی وجود دارند که الگوهای مختلفی را تولید می کنند. روش های کشف قوانین انجمنی، طبقه بندی داده ها و خوشه بندی از عمده ترین راهکارهایی محسوب می شوند که به تولید الگوهای خاص می پردازند.
طبقه بندی(classification):
پایگاه داده ها منبع بسیار غنی از اطلاعات پنهان است که می توان به کمک این اطلاعات تصمیمات هوشمندی را اتخاذ نمود. در این میان طبقه بندی و تخمین دو شکل از تحلیل داده ها محسوب می شوند که می توان به کمک آنها مدلی جهت توصیف داده ها استخراج کرد و یا برای داده های بعدی جهتی متصور شد. بدین وسیله داده هایی با حجم بالا نیز بهتر فهمیده می شوند. روش های نظارت شده ای مانند طبقه بندی و تخمین تلاش می کنند تا رابطه ی میان صفات خاصه ی ورودی (که گاه متغیرهای مستقل نامیده می شوند) را با یک یا چندین صفت خاصه هدف(که گاه متغیر وابسته نامیده می شوند) کشف کنند. درنهایت این رابطه با یک ساختار به عنوان مدل نمایش داده می شود.
با کمک این مدل و با شرط داشتن صفات خاصه ی ورودی می توانیم مقدار صفت خاصه هدف را تخمین بزنیم. به عبارت دیگر با کمک مدل قادر هستیم نمونه ها را به یکی از چندین طبقه ی تعریف شده منتسب و یا مقدار تعیین شده ای را برای صفت خاصه هدف تعیین کنیم. فرایند ساخت مدل یک فرایند دو مرحله ای است، که در مرحله اول با کمک مجموعه داده های آموزشی که برچسب کلاس تمام نمونه های آن مشخص است، مدل ساخته می شود. این مرحله به نام مرحله ی یادگیری شناخته می شود. در مرحله دوم با کمک مجموعه داده های آموزشی که در آن معمولا برچسب کلاس ها نامعلوم است، مدل بدست آمده اعتبارسنجی می شود. درواقع ارزشیابی مدل با توجه به اینکه کلاس چه تعداد از نمونه داده های آزمایشی درست تخمین زده شده است، محاسبه می شود.
روش های طبقه بندی یا دسته بندی:
درخت های تصمیم(decision tree):
درخت تصمیم در داه کاوی مدلی است که جهت نمایش طبقه کننده ها و رگرسیون ها استفاده می شود. همانطور که از نام آن مشخص است، این درخت از تعدادی گره و شاخه تشکیل شده است. در درخت تصمیمی که عمل طبقه بندی را انجام می دهد، برگ ها بیانگر کلاس ها هستند. در هر یک از گره های دیگر با توجه به یک یا چند صفت خاصه تصمیم گیری صورت می گیرد. درخت تصمیم به دلیل سادگی و قابل فهم بودن تکنیک محبوبی در داده کاوی محسوب می شود. به عبارت دیگر درخت تصمیم خود به تنهایی همه مطالب را توصیف می کند و نیاز به فرد خبره ای نیست تا خروجی را تفسیر کند. در واقع این یک روش گرافیکی است.

شکل درخت تصمیم.
ماشین بردار پشتیبان(SVM):
به جرات می توان گفت الگوریتم های ماشین بردار پشتیبان از دقیق ترین و نیرومندترین الگوریتم های داده کاوی بشمار می رود. این شیوه ی جدید می تواند برای طبقه بندی داده های خطی و غیر خطی استفاده شود. در سالهای اخیر به دلیل ارائه نتایج خوب، این الگوریتم ها به یک تکنیک متداول برای طبقه بندی تبدیل شده اند. با وجود آنکه استفاده از الگوریتم های ماشین بردار پشتیبان در مقایسه با برخی از روش های دیگر مثل شبکه های عصبی راحت تر است، اما به دلیل عدم آشنایی کاربران با جزئیات آن، استفاده کنندگان از آن نتایج مناسبی را بدست نمی آورند. چنانچه بخواهیم بطور خلاصه بیان کنیم، الگوریتم های ماشین بردار پشتیبان با کمک یک نگاشت غیرخطی فضای داده های آموزشی را به یک بعد بالاتر تبدیل می کند و سپس در این بعد جدید به دنبال ابر صفحه ای است که نمونه های یک کلاس را از کلاس های دیگر جدا کند. با یک نگاشت غیر خطی مناسب، مجموعه داده های دو کلاسی می توانند توسط یک ابر صفحه جدا شوند. الگوریتم های ماشین بردار پشتیبان علیرغم مزایای فراوانی که دارند دارای محدودیت هایی نیز هستند. این الگوریتم ها فقط بر روی داده های با مقدار واقعی کار می کنند و انواع دیگر داده ها باید به داده های عددی تبدیل شوند. این الگوریتم ها اجازه فقط دو کلاس را می دهند.
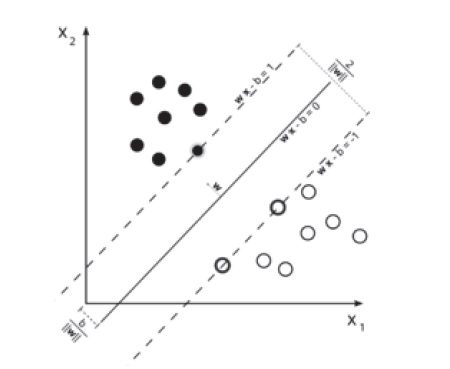
شکل الگوریتم SVM.
روش گرادیان تصادفی نزولی(Stochastic gradient descent):
روش های تصادفی گرادیان از پیاده سازی تندترین کاهش(Steepest descent) با جایگزینی بردارهای گرادیان و ماتریس هسین(Hessian matrix) با تقریب های مناسب به دست آمده است. تقریب های مختلف، به الگوریتم های مختلف با درجه پیچیدگی منجر می شود. روش های به دست آمده به طور کلی الگوریتم های گرادیان تصادفی نام دارند. الگوریتم های گرادیان تصادفی حداقل دارای دو هدف می باشند : اول این که آنها باید اطلاعات آماری دقیق سیگنال( از جمله کواریانس و کراس کواریانس و…) را بدانند اما در عمل به ندرت این ها در دسترس هستند. روش های گرادیان تصادفی به وسیله مکانیزم یادگیری ، آن ها را به تخمین اطلاعات آماری قادر می سازد. دوم این که این روش ها دارای مکانیزم ردیابی است که آن ها را قادر می سازد که تغییرات اطلاعات آماری سیگنال را پیگیری کنند. این دو قابلیت ترکیبی یادگیری و ردیابی دلایل اصلی استفاده از روش گرادیان تصادفی و فیلترهای تطبیقی می باشد.
جنگل تصادفی(random forest):
جنگل تصادفی درخت های تصمیم زیادی را تولید می کند. برای طبقه بندی یک شیء جدید از برداری ورودی را در انتهای هریک از درختان جنگل تصادفی درختان قرار می دهد. هر درخت به ما یک طبقه بندی می دهد و می گوییم این درخت به آن کلاس رای می دهد. جنگل طبقه بندی ای که بیشترین رای را داشته باشد انتخاب می کند.
هر درخت به صورت زیر تشکیل می شود:
١-اگر N تعداد حالت ها در مجموعه داده های آموزش باشد، N حالت را بصورت تصادفی با جایگذاری از داده های اصلی، نمونه گیری می کنیم. این نمونه مجموعه کار برای درخت می باشد.
۲-اگرM متغیر داشته باشیم و m را کوچکتر از M در نظر بگیریم به طوری که در هر گره، m متغیر بصورت تصادفی از M انتخاب می شوند و بهترین جداسازی روی اینm متغیر برای جداسازی گره استفاده می شود. مقدار m در طول ساخت جنگل ثابت در نظر گرفته می شود.
٣-هر درخت به اندازه ممکن بزرگ می شود. هیچ هرسی وجود ندارد.
شرح پروژه:
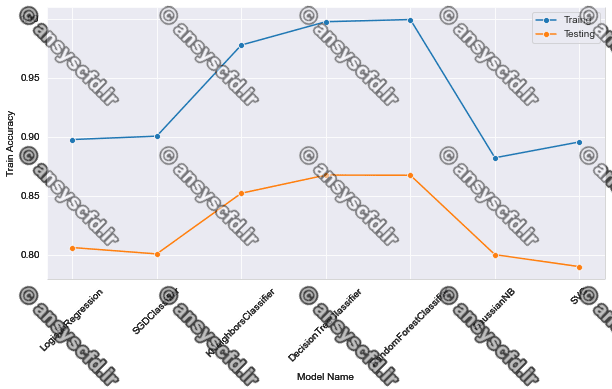
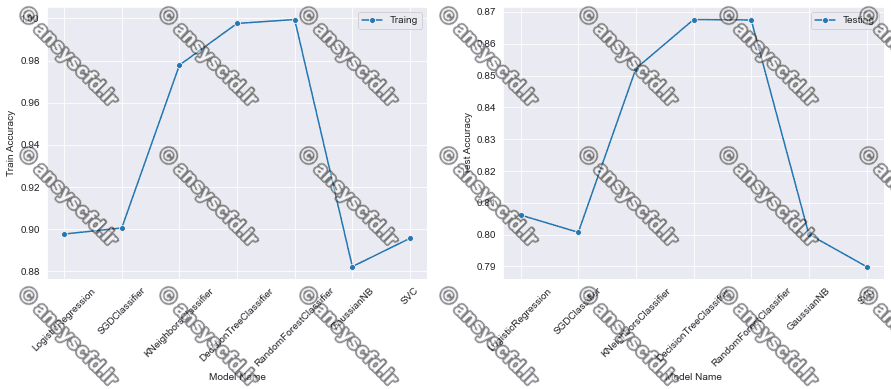
در این پروژه دسته بندی حملات سیستم تشخیص نفوذ مبتنی بر شبکه با تکنیک های مختلف یادگیری ماشین بر روی مجموعه داده NSL KDD در نرم افزار پایتون(Jupyter Notebook) انجام شده است. الگوریتم های دسته بندی مختلفی برای تشخیص حملات در سیستم تشخیص نفوذ بکاربرده شده اند که عبارتند از رگرسیون لجستیک، جنگل تصادفی، K-نزدیکترین همسایه، درخت تصمیم، ماشین بردار پشتیبان، بیز ساده، و گرادیان تصادفی نزولی.
مجموعه داده ها:
یکی از مشهورترین مجموعه های داده که برای ارزیابی و ساخت سیستم های تشخیص نفوذ مبتنی بر شبکه ایجاد شده است، مجموعة KDD CUP99 است که دارای پنج میلیون نمونه داده برای آموزش و دو میلیون نمونه داده برای آزمایش است. تولایی و همکارانش در سال ۲۰۰۹، با انجام آزمایش هایی بر روی این مجموعه داده، تعدادی مشکل را به عنوان مشکلات این مجموعه داده مطرح کردند و با ارائه دلایلی آن را برای انجام تحقیق و آزمایش مناسب ندانستند. از نظر آنها، این مجموعه داده دارای مشکلاتی است که باعث می شود مدل های ساخته شده براساس آن، قدرت تعمیم پایینی داشته باشند. وجود تعداد زیادی نمونه های تکراری هم در مجموعه آموزشی و هم در مجموعه آزمایشی، وجود نمونه های زیادی با مقادیر ناقص و اشتباه و … ، از جمله مشکلاتی است که برای این مجموعه داده عنوان کرده اند.آنها با انجام پیش پردازش هایی بر روی مجموعه داده 99KDD CUP ، مجموعه داده ای با عنوان NSL KDD CUP99 را معرفی کردند که این مجموعه دارای ۴۱ ویژگی است که این ویژگی ها، بیانگر خصوصیات یک ارتباط بین دو نقطه از یک شبکة بزرگ کامپیوتری مانند اینترنت هستند. داده ها در این مجموعه داده به دو طبقه رفتار عادی( Normal ) و رفتار غیرعادی( Anomaly) تقسیم شده اند. نوع رفتار عادی( Normal) بیانگر معمولی و بی خطر بودن ارتباط بین دو نقطه است و نوع رفتار غیرعادی( Anomaly) بیانگر حمله و خطرناک بودن ارتباط می باشد. تعداد نمونه های آموزشی این مجموعه داده تقریبا ۱۲۶ هزار و تعداد نمونه های آزمایشی آن تقریبا ۲۳هزار هستند. در این پروژه، به منظور طراحی و ارزیابی روش پیشنهادی برای کشف نفوذ و همچنین انجام آزمایش بر روی مدل کشف نفوذ و به دست آوردن نتایج آن، از مجموعه ی داده NSL-KDD CUP99 استفاده شده است. حمله کننده ها با برقراری ارتباط در سطح شبکه و با سایر کامپیوترهای داخل شبکه، به وسیله فرستادن و گرفتن بسته های شبکه، جریان ارتباط را فعال نگه می دارند و به وسیله محتویاتی که داخل بسته ها قرار میدهند و جواب هایی که از سایر کامپیوترها دریافت می کنند، می توانند با شرایط شبکه و کامپیوترهای آن آشنا شوند و به دنبال راه های نفوذ بگردند.
حملات مجموعه داده:
حملات داخل مجموعه داده به چهار دسته زیر تقسیم می شوند:
١- حمله DoS: در این نوع از حمله، حمله کننده با افزایش ترافیک روی شبکه و یا مشغول کردن بیش از حد سخت افزارهای موجود، قصد دارد مانع از خدمت رسانی به کاربرهای دیگر شود یا اینکه خود تمام توان منابع را برای اهداف خود در اختیار بگیرد.
۲- حملة U2R: حمله کننده با دسترسی به حساب کاربری یک کاربر عادی، قصد دارد به تعدادی از فراخوانی های سیستمی سطح ریشه سیستم عامل دسترسی پیدا کند و منابع سیستم را در اختیار خود بگیرد.
3- حمله R2L : حمله کننده یکی از کاربران سیستم است و می تواند بسته های داده به سمت سیستم عامل بفرستد اما به همه قابلیت های سیستم دسترسی ندارد و قصد دارد به فراخوانی های سیستمی سطح ریشه سیستم عامل دسترسی داشته باشد.
۴- حمله Probing : حمله کننده اطلاعات شبکه و کامپیوترهای متصل به آن را جمع آوری می کند و با استفاده از این اطلاعات، راههای نفوذ به سیستمها و منابع آنها را پیدا می کند.
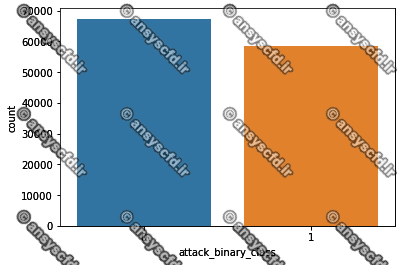
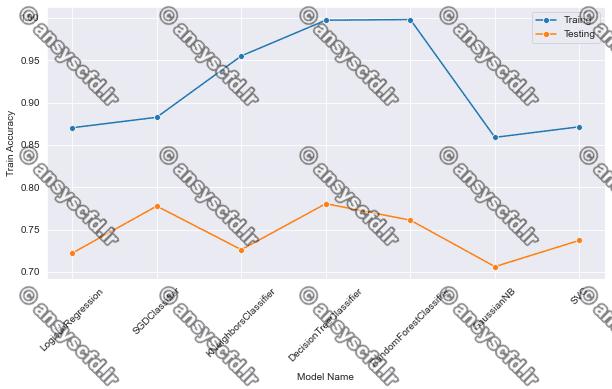
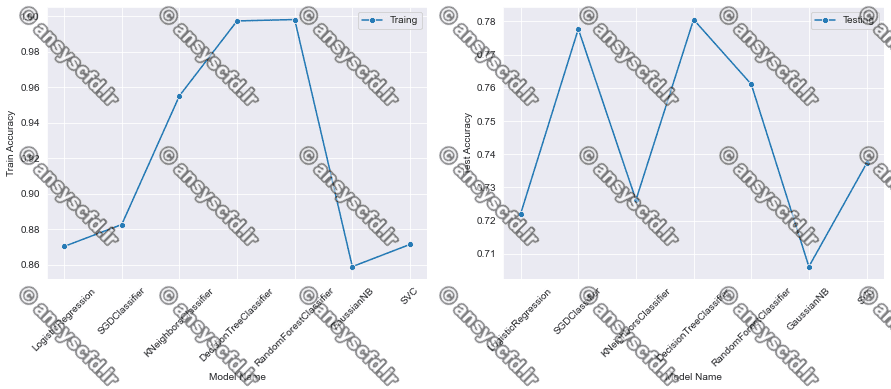
نمونه نتایج: