
توضیحات
پروژه متلب قطعه بندی و بخش بندی تصاویر MRI تومور مغزی با استفاده از الگوریتم خوشه بندی فازی(FCM) بهبودیافته
در علم پزشکی به منظور بررسی ساختارهای داخلی بدن و ارزیابی تغییرات بافت های بدن انسان و بسیاری از موارد تشخیص بیماری از تصویربرداری پزشکی استفاده می گردد. در بین تصاویر پزشکی معرفی شده تصویر MRI از کیفیت بالاتری برخوردار بوده و برخلاف روش های دیگر تصویربرداری که از پرتوهای یونساز استفاده می کنند در این تصویر از امواج الکترومغناطیس قوی با فرکانس رادیویی استفاده می گردد که در نتیجه این روش تصویربرداری برای انسان مضر نمی باشد. به دلیل ویژگی های اشاره شده در حال حاضر این روش تصویربرداری در علم پزشکی بیشترین کاربرد را دارد.
اولین مرحله در تحلیل تصاویر MRI مغز تفکیک سه بافت مشخص مغز از یکدیگر می باشد که ویژگی خاص این بافت ها و هم چنین برخی از مشکلات موجود در دستگاه تصویربرداری MRI موجب شده که بخش بندی این تصاویر به موضوعی مهم در زمینه پردازش تصاویر پزشکی تبدیل شود. به همین دلیل روش های بسیار زیادی برای بخش بندی این تصاویر ارائه گردیده است که گستردگی روش های ارائه شده در این زمینه قابل مقایسه با تمامی مطالبی است که در حوزه بینایی ماشین و پردازش تصویر مطرح می گردد، به دلیل اینکه اکثر مطالب ارائه شده در حوزه بینایی ماشین و پردازش تصویر می توانند به عنوان مبنایی برای ارائه الگوریتم های مستقل بخش بندی قرار گیرند. در راهکارهای مقدماتی ارائه شده در این زمینه معمولا اقدامات مستقلی برای حذف عوامل مزاحم از قبیل نویز و غیر یکنواختی شدت روشنایی صورت می گرفت که در واقع تصویر اصلی فیلتر می شد. به دلیل اینکه در تصاویر پزشکی اطلاعات موجود در تصویر از اهمیت بالایی برخوردار می باشند لذا فیلترکردن تصویر به نوعی موجب حذف جزئیات از تصویر می گردد. به منظور جلوگیری از این مشکل استفاده از فیلترینگ در سال های اخیر در این زمینه کاملا متوقف شده و تلاش هایی در زمینه تقویت و بهبود الگوریتمهای بخش بندی صورت گرفته است که حجم وسیع کارهای انجام شده در زمینه گسترش و بهبود الگوریتم FCM استاندارد نیز در راستای این هدف می باشد.
تصاویر MRI
در دهه ۱۸۶۰ جیمز کلارک ماکسول اسکاتلندی متوجه این نکته شد که خطوط نیروهای مغناطیسی را میتوان به صورت ریاضی بیان نمود. برخی از معادلات ماکسول ثابت می کنند که میدانهای مغناطیسی و الکتریکی با یکدیگر زاویه ۹۰ درجه می سازند. او همچنین نشان داد که میدان مغناطیسی القا شده به صورت فنری (Spiral) و عمود در خلاف جهت جریان الکترونی که آن را می سازد حرکت می کند و سرعت آن در خلا نیز برابر سرعت نور می باشد. ماکسول هم چنین سرعت و جهت امواج الکترومغناطیس را محاسبه و علاوه بر امواج ماوراء بنفش و مادون قرمز وجود سایر امواج را نیز پیشگویی کرد. هشت سال بعد هانریش هرتز آلمانی به وجود امواج نامرئي الكترومغناطیسی پی برد و اذعان نمود که تمام امواجمذکور را می توان بر اساس مقدار فرکانس آنها مشخص نمود.
تمام این حوادث وضعیت را برای آقای ويلهم کنراد رونتگن فراهم آورده بودند تا او اشعه ایکس را کشف کند. این اشعه جزو امواج الکترومغناطیس و با فرکانس بالا می باشد. بعد از او در سال ۱۹۸۶ نیز فردریک ژولیه و ماری کوری اشعه گاما را کشف کردند. با کشف آنها این مسئله روشن شد که انرژی امواج با فرکانس بالا را میتوان تشخیص و اندازه گیری نمود. هم چنین آسیبهای بیولوژیکی این تشعشعات نیز به اثبات رسید.
با شروع قرن بیستم، عصر اتم نیز آغاز شد. فیزیکدانها و دانشمندان زیادی، قسمتی از روشهای NMR و MRI را پی ریزی کردند. در سال ۱۹۴۶ دو فیزیکدان آمریکایی به نام فلیکس بلوچ و ادوارد پارسل که به طور جداگانه بر روی اتم ها کار میکردند متوجه شدند که اگر لوله آزمایشی را که محتوی ماده ای خالص می باشد با امواج مغناطیسی، انرژی دار کرده و مورد بمباران امواج رادیویی قرار دهند، اتمها تهییج شده و سپس با طیفی که متناسب با اتم های مورد آزمایش است شروع به پاسخ دادن می کنند. آنها این سیگنال ها را آشکار کرده و براساس مقدار فرکانس شان به صورت تصاویر اسپکتروسکوپی ثبت نمودند به این ترتیب بنیان تشدید مغناطیسی هسته ای که مقدمه ای بر MRI بود گذاشته شد(سرانجام بلوچ و پارسل موفق به اخذ جایزه نوبل در سال ۱۹۵۲ شدند).
در مدت ۲۵ سال پس از این کشف بیش از هزار دستگاه NMR ساخته و هزاران متخصص اسپکتروسکوپی روانه عرصه بین المللی شدند و بدین ترتیب اسپکتروسکوپی پیشرفت کرد. محققین، انواع و اقسام آزمایش ها و تجزیه و تحلیل های NMR را به صورت مصنوعی انجام دادند. اما به کارگیری آن برای تصویربرداری از بدن انسان از لحاظ آنها نه تنها غیر ممکن بلکه امری بسیار احمقانه بود.
در سال ۱۹۷۰ پزشک و فیزیک دان آمریکایی به نام دکتر ریموند دامادین که فردی بسیار فهیم و آینده نگر بود تصمیم گرفت اسکنری را برای تصویربرداری از بدن انسان بسازد. و همین مسئله، نقطه عطفی را در دنیای تصویربرداری به وجود آورد. او در آزمایش های خود، سلول های بدخیم را از طریق جراحی وارد بدن موش ها نمود و سپس آنها را مورد آزمون NMR قرار داد. دامادین متوجه شد که بافت توموری موش ها به تحریک مغناطیسی پاسخ می دهد و اگر موش ها را با یک پالس تشدید کننده بمباران کند، هنگامی که گشتاور دوقطبیهای مغناطیسی به حالت تعادل و آرامش می رسند هریک از بافت های سالم و توموری یک نوع سیگنال خاص خود را منتشر می کنند. این سیگنالها بر حسب اینکه مربوط به بافت های سالم یا ناسالم باشند میتوانند کنتراست خاصی را بر روی تصویر ایجاد کنند. همین مسئله باعث شد تا فکر ساخت دستگاه تصویربرداری به مغز وی خطور کند.
دکتر دامادین در اوایل دهه ۱۹۷۰ متوجه شد که ساختمان آب در تصویربرداری MRI عنصری بسیار حیاتی است. زیرا هر مولکول آب درواقع یک دو قطبی بسیار قوی است، علت آن است که الكترون های مدار هیدروژن زمان بیشتری را در مدارهای اطراف اتم اکسیژن می گذارنند، این وضعیت باعث ایجاد یک منبع قوی برای تولید سیگنال های MR می شود. دامادین ثابت کرد سیگنال های فوق را می توان به صورت تصویری آشکار و ثبت نمود. او و همکارانش جهت تصویربرداری کل بدن انسان مدت ۷ سال را برای طراحی و ساخت اولین اسکنر MRI صرف کردند. پس از فراز و نشیبهای فراوان بالاخره در روز سوم ژولای ۱۹۷۷ اولین تصویر دانسیته پروتون از بدن انسان تهیه شد. تصویربرداری فوق به مدت ۴ ساعت و ۴۵ دقیقه به طول انجامید. دکتر دامادین نام اولین اسکنر خود را سرکش گذاشت که درواقع نشاندهنده عزم، بی باکی و خستگی ناپذیری او در ساخت دستگاه مذکور بود. این دستگاه اکنون در مرکز تکنولوژی اسمیتسون واشنگتن قرار دارد.
روش تصویربرداری MR براساس تحریک پروتون هیدروژن مولکول های آب موجود در بافت و سپس دریافت و پردازش سیگنال های به دست آمده از آنها انجام می پذیرد. در هر سانتی متر مکعب از بافت نرم، میلیاردها هسته هیدروژن(پروتون ) وجود دارد. ابتدا این پروتون ها یا مغناطیس های کوچک به طور نامرتب در امتدادهای مختلفی قرار دارند به طوری که برآیند نیروهای مغناطیسی آنها برابر صفر است. پس از قرار گرفتن در یک میدان مغناطیسی خارجی قوی، پروتونها سعی می کنند خود را در راستای میدان مغناطیسی خارجی قرار دهند. برآیند میدان مغناطیسی پروتون ها، برداری در جهت میدان مغناطیسی خارجی خواهد بود که به آن بردار مغناطیسی برآیند می گویند.
با اعمال میدان های مغناطیسی گرادیانی(امواج رادیویی) به میدان یکنواخت خارجی، میدان مغناطیسی برآیند در هر جزء کوچک از جسم با اجزاء کناری، تفاوت کرده و درنتیجه بردار برآیند در آن جزء کوچک منحرف میشود. زاویه انحراف بستگی به شدت امواج رادیویی و مدت زمان تابش دارد و میدان مغناطیسی امواج رادیویی عمود بر میدان خارجی، اعمال می گردد.
با قطع امواج رادیویی، بردار برآیند با یک حرکت تقدیمی خود را در جهت میدان مغناطیسی خارجی(راستای قبل از اعمال امواج رادیویی قرار می دهد. این بازگشت در یک سیم پیچ، یک جریان القایی به وجود می آورد که همان سیگنال الکتریکی MR است و به آن سیگنال « واپاشی القایی آزاد » گویند.
قطعه بندی تصویر:
تصاویر و تحلیل آنها یکی از راه های انتقال اطلاعات می باشد. اطلاعات موجود در تصاویر و نوع آنها با توجه به کاربردشان متفاوت می باشند. انواع تصاویر عبارتند از : تصاویر طبیعی، تصاویر ماهواره ای، تصاویر فرا صوت، تصاویر سنجش از راه دور و تصاویر پزشکی که ناحیه بندی هر یک از آن ها نیاز به الگوریتم خاصی دارد و هر یک نیز از اهمیت خاصی برخوردار است. عموما اولین مرحله در تحلیل تصویر دیجیتال ناحیه بندی است. تقسیم تصویر به نواحی همگن از لحاظ یک ویژگی معین و یا خوشه بندی پیکسل ها به زیر نواحی با معنی را ناحیهبندی تصویر(segmentation) می نامند. بعضی از کاربردهای عملی ناحیه بندی، بینایی ماشین، تصویر برداری پزشکی، تشخیص شی و سیستم های کنترل ترافیک و غیره می باشد. از بین سیستم های تصویربرداری، سیستم تصویربرداری تشخیص مغناطیسی (MRI) و مغز نگاری کامپیوتری (CT) برای تشخیص ناهنجاری های بافتی بکار می روند. استخراج اطلاعات از این تصاویر، مرحله مهمی در پردازش تصاویر پزشکی به شمار می رود و این یک مرحله پایه ای در تشخیص بیماری و درمان لازم برای آن می باشد. پردازش تصاویر پزشکی، اغلب از پیچیدگی های زیادی برخوردار است. استفاده از اطلاعات آناتومیکی که در مورد بافت های مختلف بدن در اختیار است می تواند به عنوان پایه ای برای عملیات پردازش تصویر مورد استفاده قرار گیرد.
اهمیت قطعه بندی تصاویر:
به منظور تحلیل تصاویر دیجیتال عموماً نخستین مرحله ناحیه بندی می باشد. به عبارت دیگر ناحيه بندی تصویر، یک بخش پایه ای است که وظیفه جداسازی بخش های مختلف تصویر را برعهده دارد. هدف از ناحیهبندی، تقسیم تصویر به زیر نواحی بدون همپوشانی است، بطوریکه هر جزء یا ناحیه دارای ویژگی های یکنواخت مانند شدت روشنایی، رنگ و بافت می باشد و نواحی مجاور متناسب با ویژگی ها به طور قابل توجه ای نسبت به یکدیگر دارای اختلافات می باشند.
حجم زیاد اطلاعات در بعضی از تصاویر، ناحیه بندی توسط کاربر را زمان بر خواهد کرد. از طرف دیگر ناحیهبندی انجام شده توسط یک کاربر می تواند نتایج مختلف در زمان های مختلف داشته باشد. لذا نیازمند روشی جهت ناحیه بندی خودکار تصاویر دیجیتال می باشیم. روش های ناحیه بندی خودکار، یک مکانیزم برای غلبه بر زمانبربودن ناحیه بندی دستی مجموعه داده های بزرگ ارائه می نمایند. بنابراین در طی سال های اخیر توجه محققین بسیاری به مسأله دست یابی به ناحیه بندی قابل اعتماد، معطوف شده است که یک مرحله مهم در بسیاری از کاربردهای بینایی ماشین، سنجش از دور، شناسایی هدف، تشخیص شی، پزشکی و غیره می باشد.
یکی از مهم ترین و ضروری ترین مراحل در سیستم های بینایی ماشین و پردازش تصاویر دیجیتالی ناحیه بندی و استخراج بافت های مورد نظر از تصاویر می باشد. برای مثال در تصویربرداری پزشکی برای تشخیص بیماری ها و بررسی نحوه رشد تومورها باید تصویر را ناحیه بندی کرد.
روش های قطعه بندی تصویر:
با توجه به ارائه روش های ناحیه بندی مختلف در طی سال های اخیر دسته بندی های متفاوتی نیز برای آنها ارائه شده است. روش های ناحیه بندی علاوه بر نحوه استخراج اطلاعات بسته به نوع اطلاعات بکار رفته نیز دسته بندی می شوند. بر این اساس میتوان دسته بندی های مختلفی در نظر گرفت. روش های متعددی برای انجام ناحیه بندی وجود دارد که در اینجا چند مورد بررسی می شود.
روش خوشه بندی(clustering):
اساس کار الگوریتم خوشه بندی مشابه روش طبقه بندی می باشد، با این تفاوت که از داده های آموزش استفاده نمی کند. بنابراین این روش یک روش غیر نظارتی است. برای جبران کمبود اطلاعات دادههای آموزشی، روش خوشه بندی به صورت متناوب به ناحیه بندی تصاویر و توصیف خصوصیات هر کلاس می پردازد. به بیان دیگر روش خوشه بندی، خود را به کمک اطلاعات موجود آموزش می دهد.
تعریف خوشه:
باتوجه به مجموعه اشیا داده (اشخاص، الگوهای ورودی، نمونه ها، مشاهدات و اعداد)، هدف خوشه بندی تقسیمبندی آنها به تعداد معینی خوشه (گروه ها، دسته بندی ها، یا زیر مجموعه ها) به منظور کشف ساختار زیرین و ارائه بینش های مفید برای تجزیه و تحلیل بیشتر است. با این حال هیچ تعریف دقیقی از خوشه تا حدی به دلیل ذهنیت ذاتی خوشه که مانع از قضاوت مطلق به عنوان اثر مطلوب از همه تکنیک های خوشه بندی وجود ندارد. با وجود این مشکل چند تعریف کاربردی هنوز موجود است برای مثال دنبال می کنیم:
1-یک خوشه مجموعه ای از اشیا داده است که شبیه یکدیگرند در حالیکه اشیا داده در خوشه های متفاوت با یکدیگر متفاوت هستند.
۲- یک خوشه مجموعه ای از داده ها به طوری که فاصله بین یک شی در یک خوشه و مرکز خوشه کمتر از فاصله بین این شی با مراکز هر یک از خوشه های دیگر است.
۳- یک خوشه مجموعه ای از اشیا داده است در حالیکه فاصله بین هر دو شی در خوشه کمتر از فاصله بین هر شی در خوشه و هر شی که در خوشه نیست.
۴- یک خوشه ناحیه پیوسته از اشیا داده با یک تراکم نسبتا بالا که از دیگر ناحيه متراکم به وسیله ناحیه با تراکم کم جدا می شود.
مراحل خوشه بندی:
در خوشه بندی اطلاعات باید مراحلی را در راستای رسیدن به خوشه مناسب تر انجام داد. در زیر این مراحل ذکر می شوند.
انتخاب ویژگی: ویژگی ها باید به طور مناسبی انتخاب شوند تا اکثر داده ها کلاس بندی شوند. در صورتی که در این مرحله ویژگی های انتخابی به طور نامناسب انتخاب شوند جواب نهایی، هدف مورد نظر را نتیجه نخواهد داد. لذا این بخش نقش اساسی را در روند خوشه بندی ایفا خواهد کرد.
مقیاس نزدیکی: معیاری است که میزان شباهت و یا عدم شباهت دو بردار خصوصیت را مشخص می کند. تمام خصوصیات انتخاب شده باید در محاسبه این معیار شرکت کنند و هیچ خصوصیتی نباید بر بقیه غلبه کند. فاصله اقلیدسی از نمونه های این مقیاس می باشند.
الگوریتم خوشه بندی: پس از اینکه مقیاس نزدیکی انتخاب شدند، یک الگوریتم خاص برای دسته – بندی مجموعه داده ها انتخاب می گردد. به عنوان نمونه خروجی خوشه بندی می تواند گروه های سخت ( k-means) و یا نرم ( Fuzzy c-means) باشد که هر روش دارای درجه عضویت متفاوتی است. به عبارت دیگر درجه عضویت یعنی میزان تعلق هر داده به خوشه است.
اعتبار سنجی نتایج: وقتی که نتایج خوشه بندی به دست آمد باید صحت آنها بررسی شوند. این کار معمولا بوسیله تست های مناسبی انجام می شود. در کل سه دسته معیار تست وجود دارد؛ شاخصهای خارجی، شاخص های داخلی و شاخص های نسبی.
ناحیه بندی تصویر عبارت است از تفکیک پیکسل های تصویر به نواحی مجزایی که پیکسل های هر ناحیه بر حسب ویژگی هایی مانند شدت روشنایی، بافت و یا رنگ، همگن و یکسان هستند و یا تا حد ممکن همبستگی داشته باشند. امروزه امکان تصویر برداری با دقت و کیفیت مناسب از اندام های داخلی بدن انسان همچون مغز فراهم آمده است. تمامی این تصاویر، در زمینه های پزشکی از قبیل تشخیص آسیب ها و ارزیابی آنها، تشخیص تومورها ، آماده سازی و انجام اعمال جراحی و نیز مطالعات آماری نقش بسیار مهمی را ایفا می کند. برای مثال در تصاویر درمانی، یک پزشک با استفاده از دانش خود به ناحیه بندی تصویر می پردازد. اما زمانی که تعداد تصاویر زیاد باشند و یا تغییر شدت روشنایی اشیا نسبت به یکدیگر کم باشد و تصویر از لحاظ دید انسان مناسب نباشد، ناحیه بندی بسیار زمان بر بوده و ممکن است نتایج قابل قبولی نداشته باشد.
همچنین با توجه به برخی مشکلات و محدودیت های موجود همانند نویز، ناهمگنی در تصویر، چرخش تصویر و مات شدگی روش های خودکار ناحیه بندی با چالش های زیادی روبرو می باشند. بنابراین نیاز به خود کار کردن فرایند ناحیه بندی تصویر، امری لازم و ضروری می باشد.
این عوامل مخرب به عنوان نمونه در تصاویر پزشکی به دلایل گوناگون از جمله دستگاه های تصویر برداری و یا عدم وضوح به علت ویژگیهای ذاتی بافت ها و نواحی مختلف بدن انسان رخ می دهد. در تصاویر MRI و CT نیاز به روش های ناحیه بندی دقیق تری است که برای معرفی یک روش که بتواند به خوبی با بایاس یا ناهمگنی در شدت روشنایی تصویر و یا نویز موجود مقابله نماید، تلاش می شود. بنابراین نیاز به یک روش کاملا دقیق و کارآمد با پیچیدگی الگوریتم و تابع هزینه کمتر می باشد. همانطور که بیان شد خوشه بندی یکی از روش های ناحیه بندی تصاویر می باشد که در نهایت تصاویر مورد نظر را برای کاربر به ناحیه های مجزا و قابل قبول تقسیم می کند.
انواع خوشه بندی:
خوشه بندی داده ها، به عنوان یکی از حوزه های مهم داده کاوی شناخته شده است و عبارت است از فرایند تقسیم عناصر داده ها به گروه های مختلف(خوشه ها)، به طوری که داده های موجود در یک گروه شباهت زیادی با هم دارند ولی داده های موجود در گروه های دیگر فرق دارند. یکی از تقسیم بندی هایی که برای روشهای خوشه بندی وجود دارد سلسله مراتبی(Hierarchical) و افرازبندی(Partitional) و همپوشانی است.
خوشه بندی سلسله مراتبی:
خوشه بندی سلسله مراتبی عبارت است از تشکیل متوالی گروه هایی که عضوهای آن بیشترین شباهت را به هم و یا تفکیک گروه هایی که بیشترین اختلاف را دارند. باتوجه به اینکه روش های خوشه بندی سلسله مراتبی اطلاعات بیشتر و دقیق تری تولید می کنند برای تحلیل داده های با جزئیات بیشتر پیشنهاد می شوند ولی از طرفی چون پیچیدگی محاسباتی بالایی دارند برای مجموعه داده های بزرگ مناسب نیستند.
خوشه بندی افرازبندی:
خوشه بندی افرازبندی برخلاف روشهای سلسله مراتبی که یک ساختار خوشه بندی را ارائه می کنند، تنها یک تقسیم بندی از داده ها را نمایش می دهند. روش های افرازبندی در محیط هایی با مجموعه داده های بزرگ، نسبت به روش های سلسله مراتبی که تقریبا غیرممکن می باشند، ترجیح داده می شوند. یکی از مشکلات روش های افرازبندی، انتخاب تعداد مناسب خوشه ها برای داده ها می باشد. روش های افرازبندی معمولا از طریق بهینه سازی یک تابع هدف خوشه های نهایی را تولید می کنند.
از دیگر تقسیم بندی ها برای الگوریتم های خوشه بندی دو گروه خوشه بندی سخت و نرم می باشد.
خوشه بندی نرم:
در خوشه بندی نرم از مجموعه های فازی برای خوشه بندی داده ها استفاده می شود، به طوری که هر نقطه ممکن است متعلق به دو یا چند خوشه با درجه های عضویت متفاوت باشد. در این حالت، یک مقدار عضویت مناسب به داده ها اختصاص می یابد. در بسیاری از موارد، خوشه بندی فازی بسیار طبیعی تر از خوشه بندی سخت است. لازم نیست اشیای واقع در مرزهای بین کلاس ها، حتما به طور كامل متعلق به یکی از کلاس ها باشند، بلکه درجه های عضویتی بین ۰ و 1 به آنها اختصاص داده می شود که بیانگر عضویت جزئی آنها است. درمقابل، در روش های خوشه بندی سخت داده ها به طور انحصاری گروه بندی می گردند به طوری که اگر یک دادهی خاص متعلق به یک خوشه مشخص باشد، نمی تواند متعلق به خوشه ی دیگری نیز باشد.
خوشه بندی فازی ( (FCM یا Fuzzy C-means یک تکنیک بسیار معروف برای خوشه بندی نرم است و به طور مشابه، خوشه بندی کامینز K-means هم یک تکنیک مهم برای خوشه بندی سخت می باشد.
خوشه بندی سلسله مراتبی:
خوشه بندی سلسله مراتبی روی یک مجموعه داده با یک ساختار درختی نشان داده می شود. این نمودار درختی دندروگرام نامیده می شود. یکی از ویژگی های مهم روش های سلسله مراتبی عدم وجود پیش فرض درباره تعداد خوشدها است. پس از اجرای یک خوشه بندی سلسله مراتبی، برای به دست آوردن تعداد مشخصی خوشه باید دندروگرام حاصل، از محلی مناسب برش داده شود. این کار تعدادی دندروگرام گسسته را نتیجه می دهد که هرکدام متناظر با یک خوشه خواهند بود.
خوشه بندی سلسله مراتبی به دو دسته تقسیم می شود؛ جمع شونده(Agglomerative) و تقسیم شونده(Divisive).
خوشه بندی سلسله مراتبی تقسیم شونده:
در این روش ابتدا تمام دادهها به عنوان یک خوشه در نظر گرفته میشوند و سپس در طی یک فرایند تکراری در هر مرحله داده هایی شباهت کمتری به هم دارند به خوشه های مجزایی شکسته می شوند و این روال تا رسیدن به خوشه هایی که دارای یک عضو هستند ادامه پیدا می کند.
خوشه بندی سلسله مراتبی جمع شونده یا تجمعی:
در این روش ابتدا داده ها به عنوان خوشه ای مجزا در نظر گرفته می شود و در طی فرایندی تکراری در هر مرحله خوشه هایی که شباهت بیشتری با یکدیگر دارند با هم ترکیب می شوند تا در نهایت یک خوشه و یا تعداد مشخصی خوشه حاصل شود. از انواع الگوریتم های خوشه بندی سلسله مراتبی متراکم شونده رایج می توان از الگوریتم های اتصال منفرد، اتصال میانگین، اتصال کامل نام برد. تفاوت اصلی در بین تمام این روشها به نحوه ی محاسبه ی شباهت بین خوشه ها مربوط می شود.
خوشه بندی با روش اتصال منفرد:
این روش یکی از قدیمی ترین و ساده ترین روش های خوشه بندی است و جزء روشهای خوشه بندی سلسله مراتبی و انحصاری محسوب می شود. در این روش برای محاسبه شباهت بین دو خوشه A و B از معیار زیر استفاده می شود:
![]()
که i یک نمونه داده متعلق به خوشه A و j یک نمونه داده متعلق به خوشه B می باشد. در واقع در این روش شباهت بین دو خوشه، کمترین فاصله بین یک عضو از یکی با یک عضو از دیگری است.
خوشه بندی با روش اتصال میانگین:
این روش نیز جزء روشهای خوشه بندی سلسله مراتبی محسوب می شود. از آنجا که هر دو روش خوشه بندی اتصال منفرد و اتصال کامل بشدت به نویز حساس می باشد، این روش که محاسبات بیشتری دارد، پیشنهاد شد. در این روش برای محاسبه شباهت بین دو خوشه A و B از معیار زیر استفاده می شود:
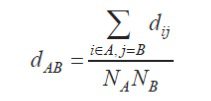
یک نمونه داده متعلق به خوشه A و ز یک نمونه داده متعلق به خوشه B می باشد. NA تعداد اعضا خوشه A و NB تعداد اعضا خوشه B است. در واقع در این روش، شباهت بین دو خوشه میانگین فاصله بین تمام اعضا یکی با تمام اعضا دیگری است.
خوشه بندی با روش اتصال کامل:
این روش همانند اتصال منفرد جزء روش های خوشه بندی سلسله مراتبی و انحصاری محسوب میشود. به این روش خوشه بندی، تکنیک دورترین همسایه نیز گفته می شود. در این روش برای محاسبه شباهت بین دو خوشه A و B از معیار زیر استفاده می شود:
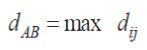
که i یک نمونه داده متعلق به خوشه A و j یک نمونه داد متعلق به خوشه B می باشد. درواقع در این روش شباهت بین دو خوشه بیشترین فاصله بین یک عضو از یکی با یک عضو از دیگری است.
خوشه بندی افرازبندی:
در الگوریتم هایی که خوشه بندی مبتنی بر افراز داده ها انجام می شود، همانطور که از نام آن مشخص است داده ها به درون چند خوشة جدا افراز میشوند. این بدین معنی است که هر نمونه داده فقط عضو یک خوشه میتواند باشد. قرارگرفتن هر نمونه در یک خوشه توسط معیارهای تشابهی که الگوریتم مشخص می کند، ارزیابی می شود. این معیارهای تشابه بر روی عملکرد الگوریتمهای خوشه بندی تأثیر به سزایی دارند. یکی از روش های خوشه بندی افراز بندی، k-means است.
خوشه بندی k-means:
الگوریتم k-means از ساده ترین الگوریتم های بدون نظارت است که مسائل خوشه بندی معروف را حل می کند و از معیار خطای مربعی استفاده می کند. این الگوریتم اولین بار توسط استارد لويرد در سال ۱۹۵۷، ارائه شده است. الگوریتمk-means از یک شیوه ساده برای ناحیه بندی تصویر به یک تعداد از پیش تعیین شده(k) خوشه استفاده می کند. ابتدا، انتخاب k مرکز برای هریک از خوشه ها میباشد. مراکز باید با دقت زیاد انتخاب شوند، زیرا مراکز مختلف، نتایج مختلف را در پی دارند. گام بعدی اختصاص دادن هر داده به نزدیکترین مرکز می باشد. وقتی همه نقاط به مراکز موجود تخصیص داده شدند، مرحلة اول تکمیل شده است و یک گروه بندی اولیه انجام می شود. در این مرحله نیاز است که k مرکز جدید برای خوشه های مرحلة قبل محاسبه شود. بعد از تعیین k مرکز جدید، مجدداً داده ها به مراکز مناسب تخصیص داده می شوند. این مرحله آنقدر تکرار می شود تا اینکه k مرکز، جابجا نشوند. این الگوریتم همواره درصدد کمینه کردن یک تابع هدف می باشد. برای اندازه گیری مشابهت و نزدیکی نقاط، از فاصله اقلیدسی استفاده می شود. این فاصله برای داده(پیکسل) iام با موقعیت Xj و مرکز Cj بصورت ![]() تعریف می شود، که در آن m || * || نرم m ام می باشد.
تعریف می شود، که در آن m || * || نرم m ام می باشد.
عموماً از نرم ۲ استفاده می شود. بنابراین تابع هدفی که تعریف می گردد، به صورت رابطه زیر می باشد، که یک رابطه مینیمم مربع خطا است.
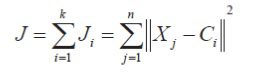
در رابطة بالا، Xj مقدار خاکستری j امین پیکسل است. n تعداد کل پیکسل ها است، C تعداد ناحیه ها است.
بنابراین می توان الگوریتمk-means را به صورت زیر اجرا نمود:
- انتخاب k تا مرکز دسته.
- سپس هر پیکسل از تصویر به نزدیکترین مرکز دسته تعلق می پذیرد.
- در این مرحله بایستی که k مرکز جدید برای خوشه های مرحله قبل محاسبه گردد.
- بعد از تعیین k مرکز جدید، مجددا داده ها را به مراکز مناسب تخصیص داده می شوند.
- دو مرحله آخر تا زمانیکه همگرایی حاصل شود، تکرار می گردند. این معیار می تواند این باشد که دیگر امکان نسبت دادن یک نمونه از یک خوشه به خوشه دیگر وجود نداشته باشد و یا اینکه بعد از چند مرحله کاهش خطای مربعی غیر محسوس گردد. در این حالت الگوریتم متوقف می شود.)
اختلاف و فاصله ای که بین پیکسل ها و مراکز دسته ها محاسبه می شود، بر پایه رنگ، شدت، بافت، موقعیت مکانی پیکسل و یا ترکیب وزنی از این ضرایب پیکسل ها می باشد.
بدلیل سادگی در پیاده سازی و پیچیدگی زمانی الگوریتم k-means بسیار متداول است. از مشکلات اساسی در این الگوریتم، می توان نیازداشتن به تعداد خوشه ها در ابتدا، حساس بودن به داده های نویزی و پرت، وابستگی نتایج نهایی به مقدار دهی اولیه و تعداد خوشه ها، گیر کردن الگوریتم در بهینه محلی و همگرایی زودرس را نام برد.
خوشه بندی هم پوشانی:
در این روش خوشه ها تاحدی بایکدیگر دارای هم پوشانی میباشند. در این خوشه بندی هر داده دارای یک درجة تعلق است، زمانی که در هر خوشه قرار می گیرد لذا یک داده می تواند با نسبت های متفاوت به چندین خوشه وابسته باشد. خوشه بندی فازی Fuzzy C-means نمونه ای از این خوشه بندی است.
خوشه بندی فازی(FCM):
برای درک بهتر خوشه بندی فازی و الگوریتم های مختلف ابتدا مفهوم مجموعه های فازی و تفاوت آنها با مجموعه های کلاسیک را بیان می کنیم.
در خوشه بندی کلاسیک هر نمونه ورودی متعلق به یک و فقط یک خوشه می باشد و نمی تواند عضو دو خوشه و یا بیشتر باشد. اما حالتی که میزان تشابه یک نمونه با دو خوشه و یا بیشتر یکسان باشد در خوشه بندی کلاسیک باید تصمیم گیری شود که این نمونه متعلق به کدام خوشه است ولی در خوشه بندی فازی یک نمونه می تواند متعلق به بیش از یک خوشه باشد.
یکی از مهم ترین و پرکاربردترین الگوریتم های خوشه بندی، الگوریتم (Fuzzy C-means (FCM می باشد. الگوریتم FCM یک الگوریتم خوشه بندی بدون نظارت و تکرار شونده ای است که تصویر مورد نظر را به K دسته تقسیم می کند. در این روش K مرکز دسته(ci, i=1,2,…,k) وجود دارد، و این مرکز دسته ها به صورت تصادفی در ابتدای اجرای الگوریتم مقدار دهی اولیه می شوند. در هر تکرار، پیکسل ها با درجه معینی، به هر دسته اختصاص می یابند که مجموع درجه عضویت هر پیکسل به تمامی دسته ها برابر مقدار ثابت یک می باشد. بنابراین هر پیکسل jام به هر دسته i ام با درجه تعلق پذیری uij تعلق می پذیرد. بنابراین هر پیکسل jام دارای k تا درجه تعلق (uij)، متناسب با هر دسته می باشد. سپس این مراکز دسته ها بروزرسانی می گردند.
وزن هر پیکسل برابر درجه تعلق پذیری آن پیکسل به آن مرکز دسته می باشد. این فرآیند تا زمانیکه همگرایی حاصل گردد، تکرار می شود. میزان فازی بودن توسط مقدار فازی ساز m تعیین می گردد. m در توان uij می باشد، و تعیین می کند uij با چه درجه ای در هنگام مینیمم سازی تابع هدف رشد یابد. تابع هدف برای حالت فازی با قرار دادن 2=m به صورت زیر می باشد.
![]()
در رابطه بالا Xj مقدار خاکستری پیکسل jام و Ci مرکز دسته i ام است. به تعداد ناحیه ها و n تعداد کل پیکسلها می باشد. همچنین مرکز هر دسته با رابطه زیر بروزرسانی می شود که حل آن توسط روش حل ضرایب لاگرانژ صورت می پذیرد.
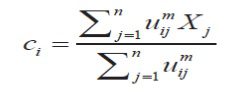
با مشتق گیری معادلات قبل نسبت به Ci (uij) ثابت و يكبار نسبت به uij (Ci ثابت)، و برابر قرار دادن آنها برای تمامی مرکز دسته ها(i=1,2,…,k) با صفر، معادله زیر برای uij بدست می آید.
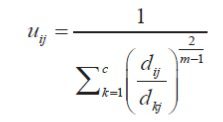
در ناحیه بندی تصویر Xj مقدار خاکستری j امین پیکسل است. n تعداد کل پیکسل ها است، C تعداد ناحیه ها است، d فاصله اقلیدسی بین XوC را نشان می دهد. U درجه عضویت پیکسل X در j امین خوشه است.
بنابراین روند حل FCM به صورت زیر است:
- انتخاب K تا مرکز دسته Ci با مقداردهی اولیه به صورت تصادفی، تجربی و یا هوشمند.
- محاسبه درجه تعلق پذیری uij برای هر پیکسل jام و برای هر دسته i ام، با استفاده از رابطه فوق
- بروزرسانی مکان جدید هر مرکز دسته
- دو مرحلة قبل تا زمانیکه همگرایی حاصل گردد، تکرار می شوند(برای مثال مکان مرکز دسته ها تغییر نکنند یا مقدار تفاوت J با مقدار تکرار قبلیش کمتر از مقدار خاصی شود.)
از معایب این الگوریتم، حساس بودن به مقدار اولیه مراکز دسته ها و نویز، تعیین تعداد مراکز و به دام افتادن در بهینه محلی می باشد. اما از نقاط قوت این الگوریتم می توان به بدون ناظر بودن و همگرایی همیشگی پاسخ اشاره کرد.
روش های بهبود خوشه بندی فازی FCM
روش FCM یک روش تکرار شونده است که سعی در بهینه سازی تابع هدف دارد. این تابع هدف نمی تواند اطلاعات مکانی پیکسل ها را بکار گیرد، و تنها مقادیر شدت رنگ پیکسل ها را بکار می گیرد. بنابراین این روش تمامی تصاویر را همانند داده های گسسته در نظر می گیرد و خوشه بندی می نماید. علاوه بر این، تابع عضویت رابطه توسط مقدار ![]() (میزان تفاوت شدت رنگ پیکسل با شدت رنگ مرکز خوشه) به تصمیم گیری درباره عضویت پیکسل ها به دسته مربوطه می پردازد. این مساله منجر به افزایش حساسیت به نویز و خوشه بندی اشتباه می شود. به منظور برطرف سازی این مشکل از روش اصلاح تابع هدف یا عضویت FCM، صورت می پذیرد. در ادامه چندین روش از اصلاحات FCM بیان می شود.
(میزان تفاوت شدت رنگ پیکسل با شدت رنگ مرکز خوشه) به تصمیم گیری درباره عضویت پیکسل ها به دسته مربوطه می پردازد. این مساله منجر به افزایش حساسیت به نویز و خوشه بندی اشتباه می شود. به منظور برطرف سازی این مشکل از روش اصلاح تابع هدف یا عضویت FCM، صورت می پذیرد. در ادامه چندین روش از اصلاحات FCM بیان می شود.
روش PCM یا Possibilistic C-Means:
در روش PCM به جای داشتن یک ترم در تابع هدف از دو ترم استفاده می شود. ترم دوم تلاش به بیشینه سازی هرچه بیشتر uij بدون محدودیت در بازه [0,1] مینماید و بنابراینuij می تواند بزرگتر از یک را نیز شامل شود. اما از اطلاعات مکانی تصویر استفاده نمی کند. تابع هدف روش PCM به صورت زیر است:
که در آن Xj پیکسلj ام، uij درجه عضویت بین پیکسل j ام و مرکز خوشه i ام، m فازی ساز که مقدار آن برابر ۲ انتخاب می شود و ni یک مقدار حقیقی مثبت است. اولین ترم سعی در کمینه سازی فاصله ویژگی پیکسل نسبت به مرکز خوشه دارد، در حالیکه ترم دوم سعی در بیشینه سازی uij تا حد ممکن دارد.این روش منجر به دسته بندی شدن داده ها تنها در یک یا دو دسته می گردد.
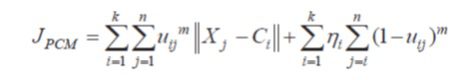
روش RFCM یا Relational Fuzzy C-Means:
در این روش یک تابع هدف اصلاح شده به منظور وارد نمودن اطلاعات مکانی به FCM ارائه شده است و الگوریتم را از دیدگاه های تغییر تابع هدف، تابع عضویت و انتخاب گروه خوشه بندی بهبود می بخشد. اما این اصلاح منجر به پیچیده شدن تابع هدف شده است. تابع هدف RFCM به صورت زیر می باشد.
که در آن Nj مجموعه ای از پیکسل های همسایه j امین پیکسل در پنجره Ω می باشد. Mj تعداد خوشه ها تاخوشه iام می باشد. و پارامتر مصالحه بین مینیمم سازی تابع هدفFCM استاندارد و تابع عضویت فازی ایجاد می کند.
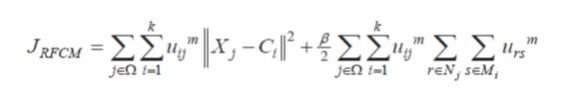
روش BCFCM یا Bias-Corrected(BC) FCM:
از آنجا که Bias Field یک تغییر در بافت تصویر است آن را به عنوان یک ویژگی اضافی در تصویر در نظر می گیرند. از این رو آن را به صورت زیر مدل می کنند:

روش BCFCM ترم جدیدی به تابع هدف اضافه می کند. این ترم امکان تاثیرپذیری خوشه بندی هر پیکسل از ویژگی های پیکسل های همسایه را فراهم می کند. درواقع از اطلاعات محلی اطراف پیکسل استفاده می کند. پارامتر اثر ترم همسایه را کنترل می کند. اطلاعات همسایه در هر تکرار محاسبه می شود و همین موضوع باعث پیچیدگی زمانی و کاهش بازدهیBCFCM شده است. تابع هدف آن به صورت زیر می باشد.
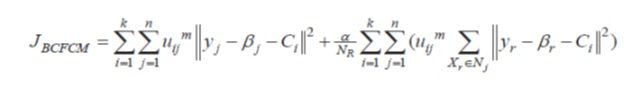
که در آن Nj مجموعه همسایگان قرار گرفته در پنجره حول پیکسل yr می باشد و NR تعداد اعضای Nj و مقدار بایاس پیکسل می باشد که در مرجع مربوطه روش تخمین آن ارائه گردیده است.
روش FCM-S
در اینجا به بیان یکی دیگر از الگوریتم های اصلاح شده برای FCM به منظور بکارگیری اطلاعات مکانی و درنتیجه خوشه بندی صحیحتر اشیا و مقابلة بهتر با نویز می پردازیم. در این روش به صورت مستقیم اطلاعات مکانی به درون تابع عضویت پیکسل ها به مراکز دسته ها، وارد شده است. این کار سبب حفظ اطلاعات تصویر تاحد بسیار قابل قبولی می شود. بدین منظور برای وارد نمودن اطلاعات مکانی در تابع هدفFCM استفاده از یک پنجرة مکانی بر روی هر پیکسل، پیشنهاد شده است. براین اساس به منظور بهره مندی از ویژگی مکانی هر پیکسل، درجه تعلق پذیری پیکسل j ام از مجموع درجة تعلق پذیری پیکسل های قرار گرفته در پنجره مربوطه، محاسبه می شود.
تابع هدف به صورت رابطه می باشد:
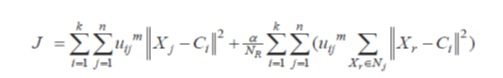
که در رابطه بالا، Nj مجموعه ی همسایگان قرار گرفته در پنجره حول پیکسل Xr و NR تعداد اعضای Nj می باشد. اثر ترم دوم را کنترل می کند.
شرح پروژه:
در این پروژه روش خوشه بندی فازی بهبودیافته RSSFCA یا robust self-sparse fuzzy clustering algorithm برای قطعه بندی و بخش بندی تصاویر مغزی MRI در نرم افزار متلب انجام شده است.
روش خوشه بندی فازی بهبودیافته پیشنهادی در مقاله زیر پیشنهاد شده است. این روش خوشه بندی فازی دارای دو مزیت می باشد.
- مزیت اول این روش آن است که از منظم سازی تحت معیار گوسی برای بدست آوردن عضویت های پراکنده مناسب استفاده می کند که سبب کاهش تداخل غیرهمگن و دستیابی به طبقه بندی بهتر نسبت به الگوریتم های FCM خود بهینه سازی شده می شود.
- مزیت دوم روش خوشه بندی فازی RSSFCA ، این است که از CCB-ADB برای دستیابی به ادغام ناحیه خودکار استفاده می کند که نسبت به استراتژی شامل نمودن اطلاعات مکانی محلی ارجحیت دارد و به روش RSSFCA کمک می کند تا به قطعه بندی بهتر تصویر نسبت به الگوریتم های FCM با اطلاعات مکانی محلی دست یابد.
تابع هدف روش خوشه بندی فازی RSSFCA مطابق مقاله مرجع به صورت زیر تعریف می شود :
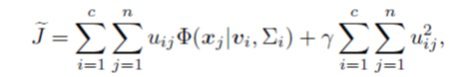
در رابطه فوق ![]() بیانگر تابع فاصله بین xj و vi ، یک ضریب موازنه استفاده شده برای کنترل تنکی عضویت ها می باشد. با تغییر مقدار تابع هدف درجات مختلفی از پایداری به نویزها نشان می دهد.
بیانگر تابع فاصله بین xj و vi ، یک ضریب موازنه استفاده شده برای کنترل تنکی عضویت ها می باشد. با تغییر مقدار تابع هدف درجات مختلفی از پایداری به نویزها نشان می دهد.
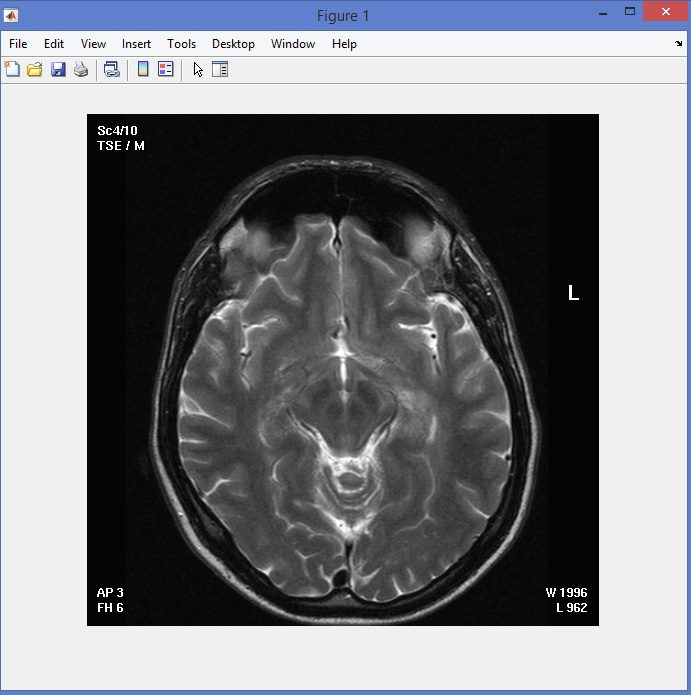
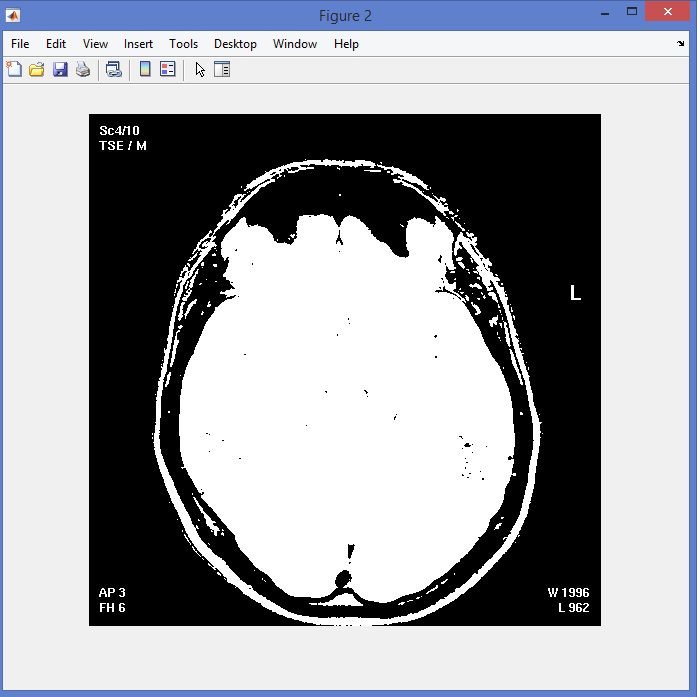
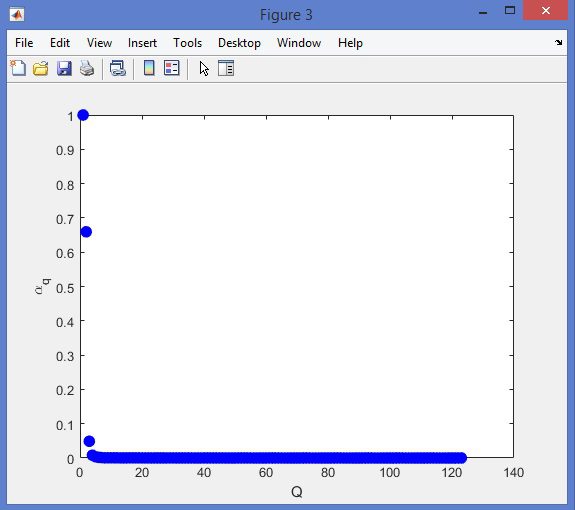
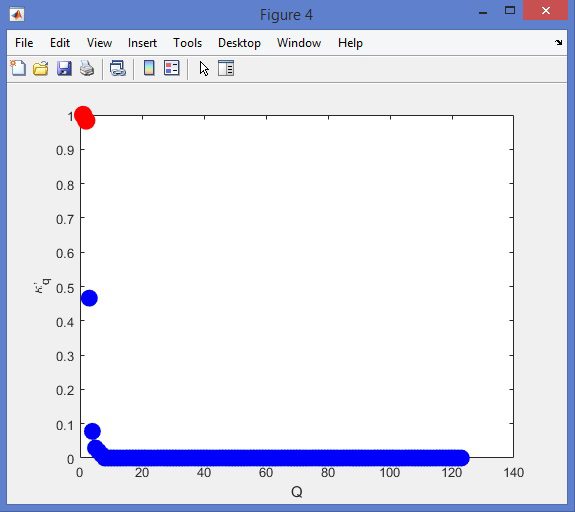
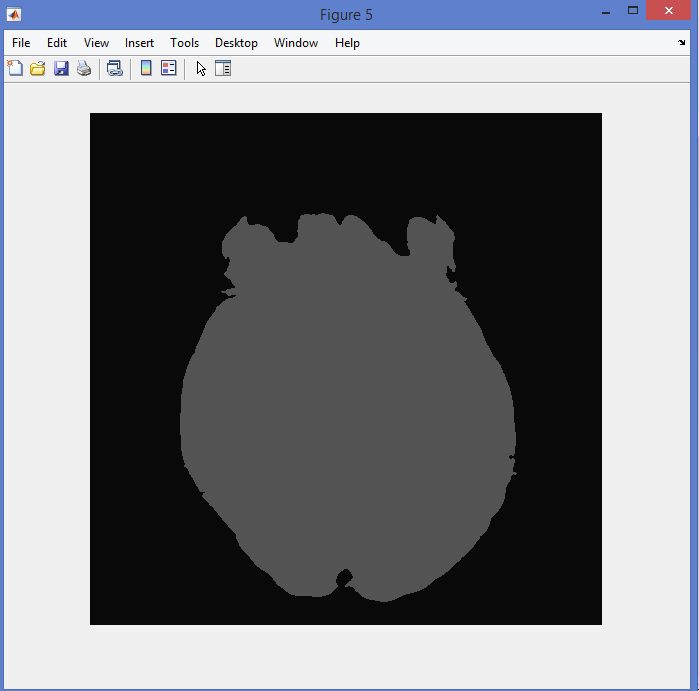
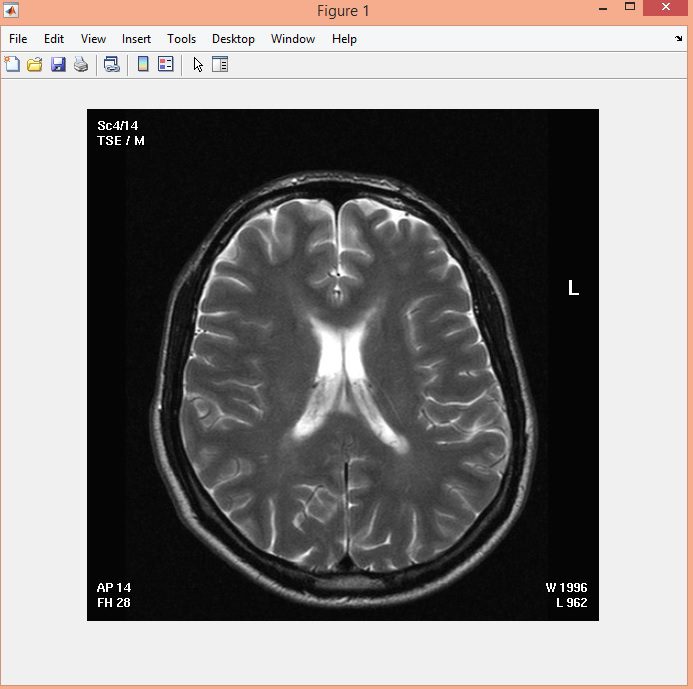
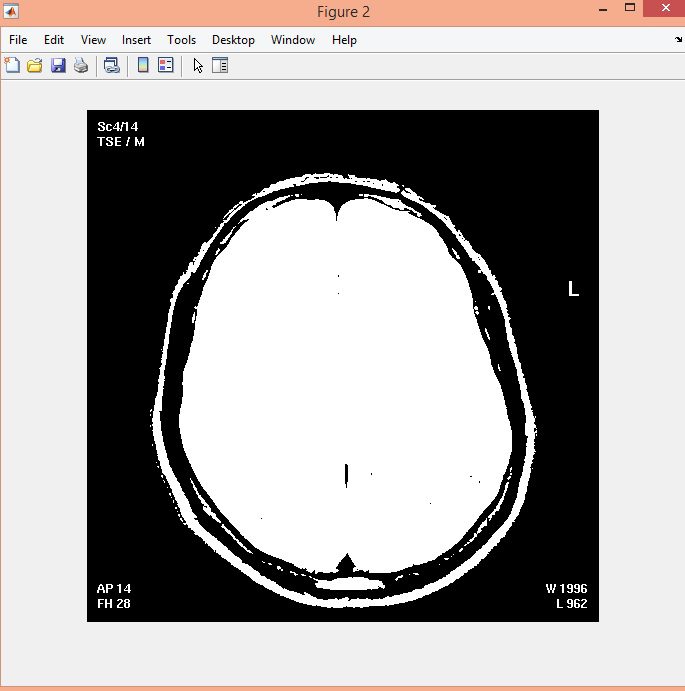
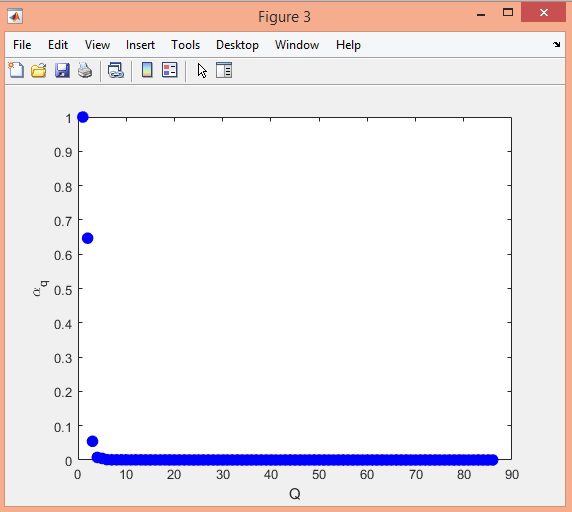
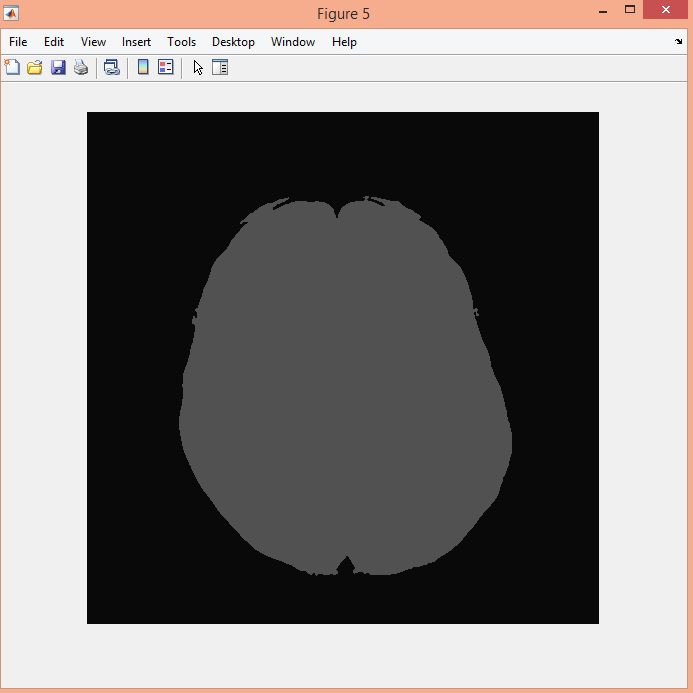
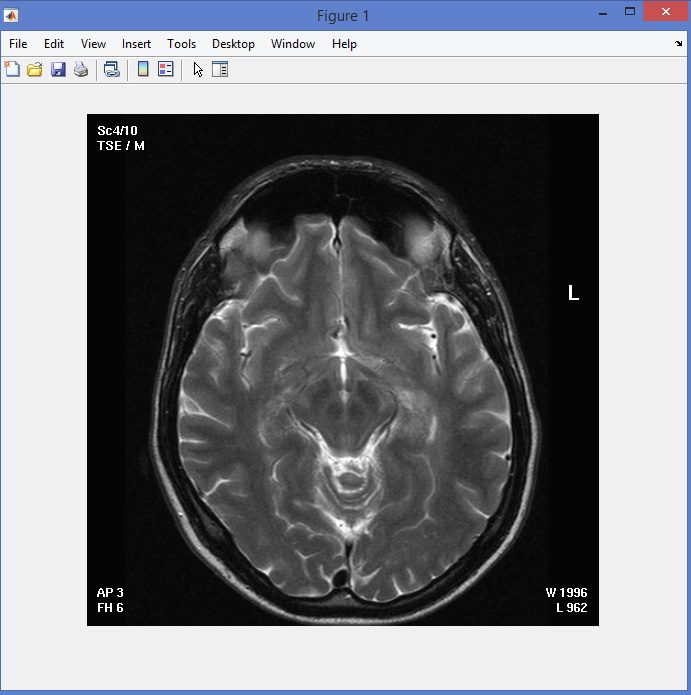
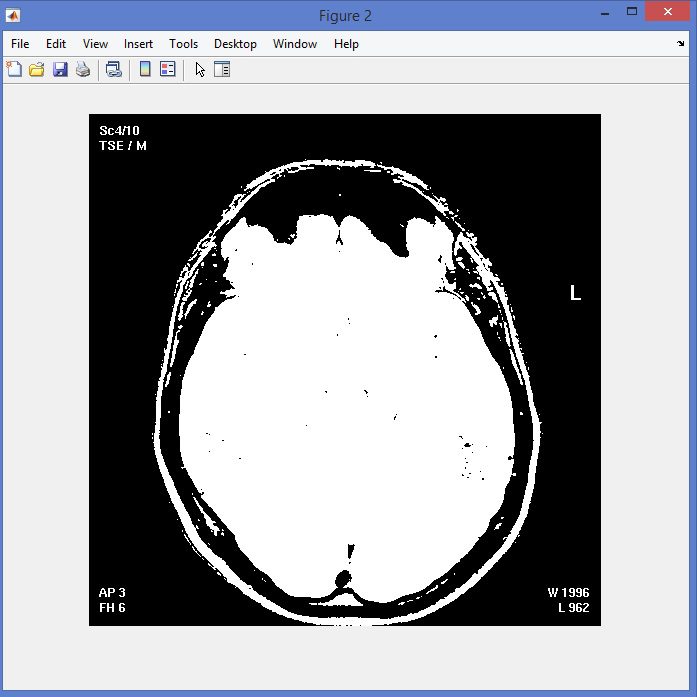
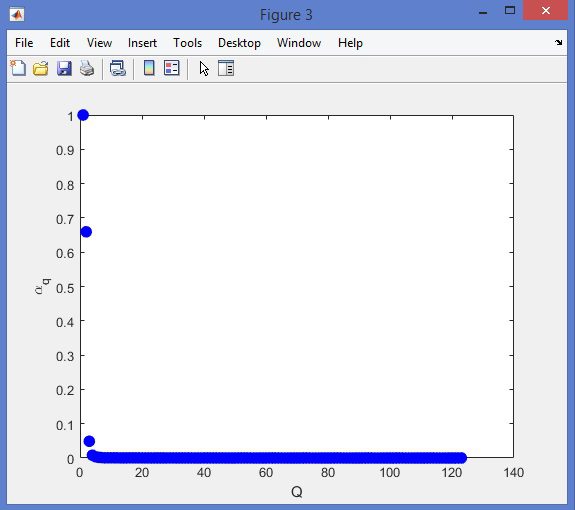
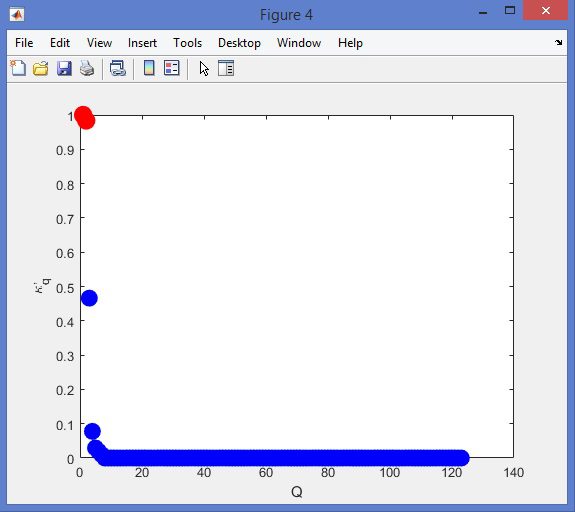
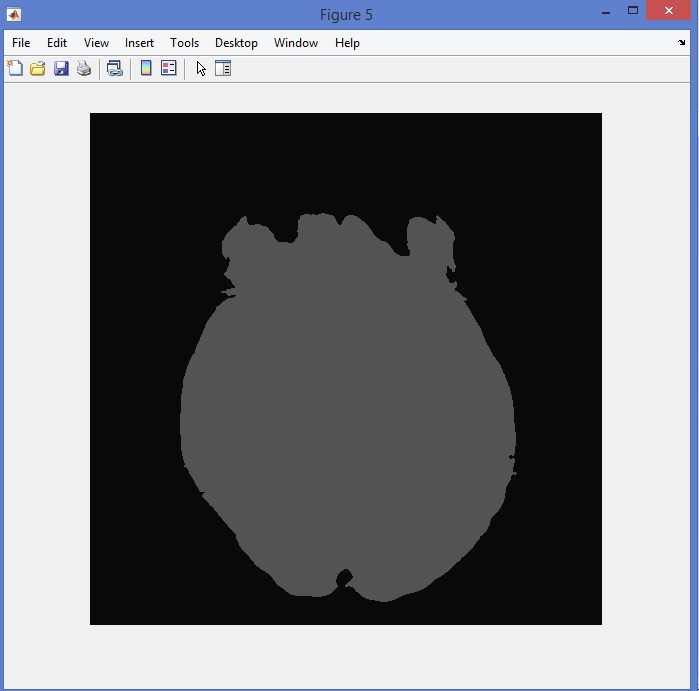
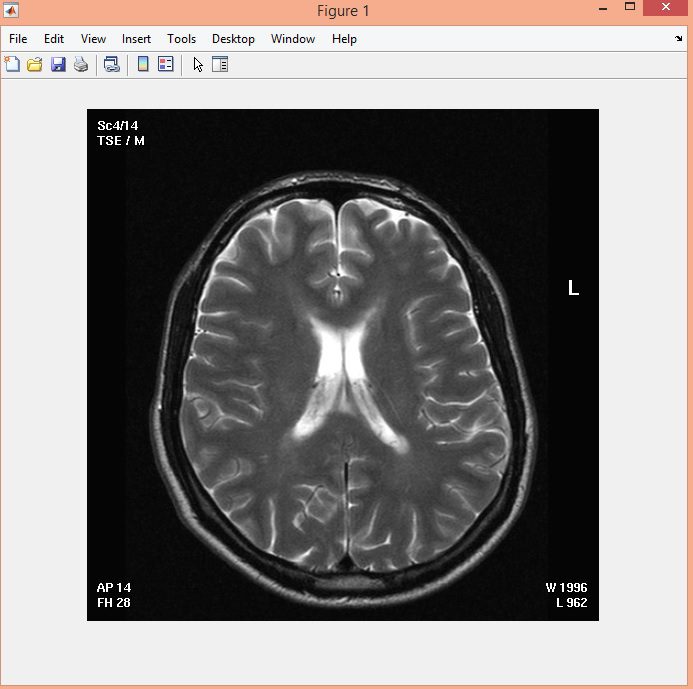
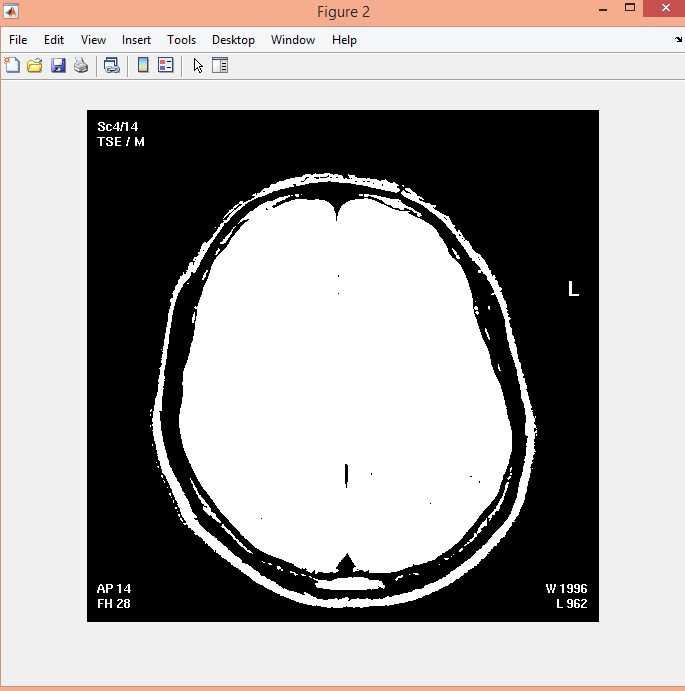
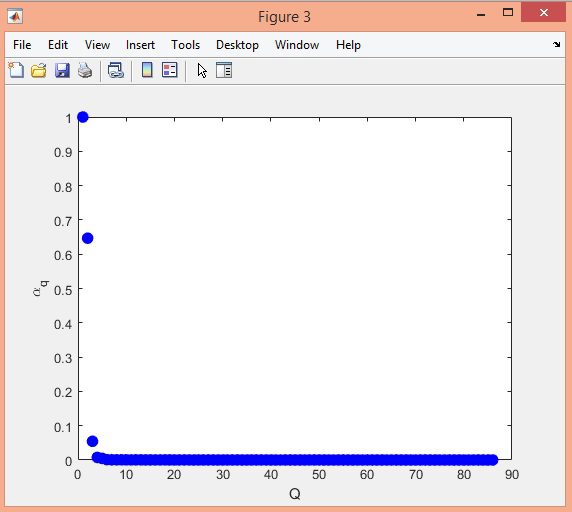
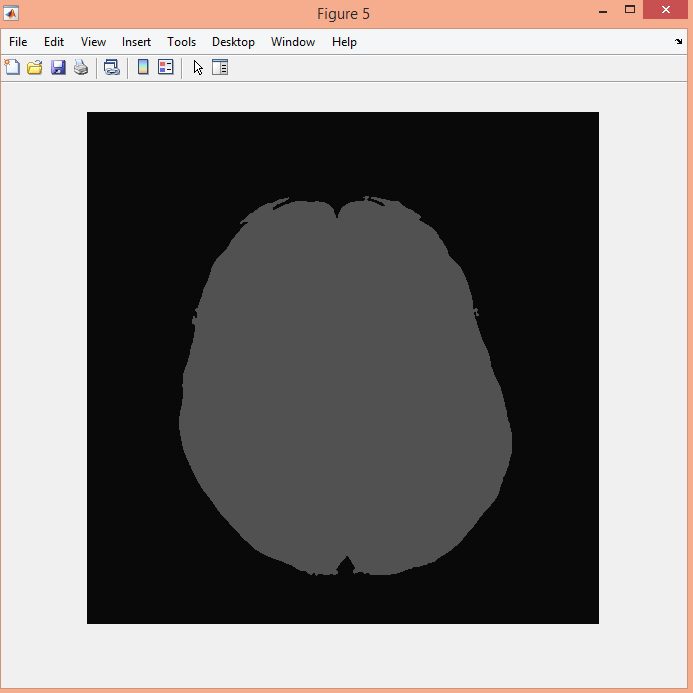
نمونه نتایج بدست آمده از قطعه بندی تصاویر MRI تومور مغزی با روش خوشه بندی فازی