توضیحات
پروژه پایتون تشخیص بیماری قلبی با استفاده از تکنیک های داده کاوی و طبقه بندهای ماشین بردار پشتیبان، درخت تصمیم، جنگل تصادفی، بیز ساده و رگرسیون لجستیک بر روی مجموعه داده کلیولند Cleveland از UCI
باتوجه به رواج بیماری گرفتگی عروق کرونری و نقش اساسی که در مرگ و میر جامعه بشری دارد تشخیص زودهنگام این بیماری توسط روش های غیرتهاجمی بسیار مورد توجه محققان واقع شده و افراد بسیاری تلاش نموده اند تا از داده های به دست آمده از روش های غیرتهاجمی مختلف و با الگوریتم ها و رویکردهای گوناگون به پزشکان در زمینه تشخیص این بیماری کمک نمایند. از جمله مهم ترین روش ها و تست های غیر تهاجمی ای که در تحقیقات مختلف سعی شده تا با استفاده از داده های به دست آمده از آنها این بیماری را تشخیص داد می توان به تست ورزش، اطلاعات بالینی، میزان و نوع املاح درون خون، سیگنال های داپلر، فوتوکاردیوگرافی و صدای قلب و غیره اشاره نمود.
داده کاوی، پایگاه ها و مجموعه های حجیم داده ها را در پی کشف و استخراج دانش، مورد تحلیل و کند و کاوهای ماشینی و (نیمه ماشینی) قرار می دهد. این روش که با حداقل دخالت کاربران همراه است، اطلاعاتی را در اختیار آنها و تحلیل گران قرار می دهد تا براساس آنها تصمیمات مهم و حیاتی را در سازمان مربوطه اتخاذ نمایند. داده کاوی در سال های اخیر، تأثیرات شگرفی در محیط های آکادمیک و صنعتی ایجاد کرده و کاربردهای فراوانی در زمینه های مختلف یافته است. به عنوان نمونه می توان به کاربردهای تجاری، مدیریت و کشف تقلب، پزشکی، ورزشی، متن کاوی و وب کاوی اشاره نمود.
تکنیک های داده کاوی به طورکلی دو گروه با نظارت و بدون نظارت تقسیم بندی می شوند. در روش های بدون نظارت متغیر هدفی تعریف نمی شود و الگوریتم داده کاوی همبستگی ها و ساختارهای بین تمام نمونه ها را جستجو می کنند. از مهم ترین روش های داده کاوی بدون نظارت، می توان به خوشه بندی اشاره کرد. اکثر روش های داده کاوی روش های با نظارت می باشند که در این روشها یک متغیر هدف از قبل تعریف شده، وجود دارد. در این روش ها نمونه های زیادی وجود دارند که مقدار متغیر هدف برای آنها از قبل مشخص می باشد؛ بنابراین الگوریتم می تواند به کمک آنها آموزش ببیند و دریابد که متغیرها و ویژگی های توصیف کننده یک نمونه با کدام مقدار متغیر هدف متناظر می باشد.
در دهه گذشته با رشد داده کاوی، مساله تشخیص بیماری قلبی به یک مساله دسته بندی تبدیل شده است و محققان الگوریتم های متعدد دسته بندی را در این زمینه به کار گرفته اند. از جمله این روش ها می توان به شبکه های عصبی، درخت تصمیم ، الگوریتم ماشین بردار پشتیبان و سیستم پشتیبانی تصمیم اشاره نمود. با توجه به پژوهش های صورت گرفته عدم ارائه نتایج قابل تفسیر برای متخصصان از مسائلی است که در حوزه تشخیص بیماری قلبی وجود دارد و زمینه را برای پژوهش بیشتر فراهم می سازد.
بیماری قلبی عمده ترین عامل مرگ و میر در دنیا است، که اولین عامل مرگ و میر و پنجمین عامل از کار افتادگی و ناتوانی محسوب می شود. در حدود ۸0% این مرگ و میرها در کشورهای سطح پایین یا سطح متوسط (در حال توسعه) رخ می دهد. در صورتی که این روند ادامه پیدا کند، تا سال ۲۰۳۰ میلادی در حدود 23.6 میلیون نفر از طریق بیماری های قلبی و عروقی(Cardio Vascular Diseases (CVDs)) خواهند مرد(عمدتا از طریق سکته های قلبی و مغزی). به علت وجود جنبه های فیزیکی فراوان در دستگاه قلب و عروقی، بیشتر بیماری های قلبی با یک جزء فیزیکی توام است، مثلا افزایش بار کاری قلب یا کاهش توانایی انجام کار به وسیله آن با یک آهنگ طبیعی. کار انجام شده توسط قلب تقریبا برابر است با حاصلضرب میزان کشش ماهیچه های قلب در مدت زمان کار. هر عاملی که باعث افزایش کشش ماهیچه یا مدت زمان انجام کار شود، کار قلب را افزایش می دهد. مثلا فشار خون بالا سبب می شود کشش ماهیچه به تناسب فشار افزایش یابد. تندی ضربان قلب با افزایش مدت زمانی که صرف انقباض ماهیچه میشود، کار قلب را می افزاید. در میان بیماری های قلبی، حمله قلبی عامل عمده ی مرگ و میر است. گرفتگی یک یا چند سرخرگ ماهیچه ای باعث بروز حمله قلبی می شود. بخشی از ماهیچه قلب که خون رسانی نداشته باشد می میرد. همیشه گرفتگی، بلافاصله بر سیگنال های الکتریکی قلب که کار تپش قلب را کنترل می کنند تاثیر ندارد و از این رو ممکن است فردی که به تازگی دچار حمله قلبی شده است، نوار قلبی طبیعی داشته باشد. هنگام حمله قلبی و پس از آن، توانایی ماهیچه قلب در تلمبه کردن خون به بدن به شدت مختل می گردد. در این موارد برای کاهش کار قلب، استراحت در بستر و اکسیژن تجویز می شود. با افزایش میزان اکسیژن هوای تنفسی، اکسیژن خون نیز افزایش می یابد و نیاز بافت ها به خون کم می شود و در واقع خون کمتری باید تلمبه شود. احتمالا بیشترین اثر مثبت اکسیژن روی خود ماهیچه قلب است. برخی راه های فرعی برای خون رسانی به ماهیچه ها وجود دارد. وجود این راه های فرعی یا آناستاموز در قلب بخشی از اکسیژن مورد نیاز بخش مسدود را تامین می کند. یکی از هدف های برنامه منظم ورزشی، فراهم آوردن فشار کافی در دستگاه قلب و عروق برای بازنگهداشتن این راه های فرعی است.
بیماری های قلبی و عروقی ارتباط نزدیکی با دینامیک خون، هندسه و مکانیک دیواره شریان دارد. گرفتگی عروق ابا سن رابطه ی مستقیم دارد. با افزایش سن فیبرهای الاستیک در جدار رگها توسط الیاف کلاژن سفت و سخت جایگزین می شود و در نتیجه شرایط برای گرفتگی عروق قلبی مساعد میشود و با تجمع چربی و ذرات دیگر، سبب بروز بیماریهای قلبی و عروقی می شود. در ابتدای قرن بیستم، ۱۰ درصد کل موارد مرگ و میرها به علت بیماری های سیستم قلبی و عروقی بوده است.
در انتهای همین قرن مرگ و میر ناشی از بیماری های قلبی و عروقی به ۲۵ درصد افزایش یافته و پیش بینی می شود با توجه به روند کنونی تا سال ۲۰۲۵ میلادی بیش از ۳۵ تا ۶۰ درصد مرگ و میر در جوامع مختلف را بیماریهای قلبی و عروقی موجب خواهد شد.
بر اساس گزارش سازمان بهداشت جهانی(WHO)، بیماری قلبی اولین دلیل عمده مرگ و میر در کشورهایی با درآمدهای بالا و کشورهای فقیر می باشد که تقریبا به یک اندازه در مردان و زنان اتفاق می افتد. تا سال ۲۰۳۰ در حدود ۷6% از مرگ و میرها در دنیا، به علت بیماری های غیر قابل انتقال (غیر واگیر) خواهد بود.
بیماری های قلبی عروقی (CVD)، همچنین در حال افزایش هستند و بخش عمده ای از بیماری های غیر واگیر را تشکیل می دهند. در سال ۲۰۱۰ پیش بینی ای انجام شده که انتظار می رود ۲۳ میلیون نفر در سراسر جهان به بیماری های قلبی عروقی مبتلا باشند. درحقیقت بیماری های قلبی و عروقی خود به تنهایی بزرگترین علت مرگ خواهد بود، به عبارتی یک سوم کل مرگ و میر در دنیا را تشکیل میدهد.
برخی از آسیب های قلبی و عروقی:
بسیاری از بیماری های دستگاه گردش خون، مربوط به رگ های خونی است که از آن دسته آسیب ها می توان به آنوریسم ضعف دیواره سرخرگ اشاره کرد که باعث افزایش قطر آن می شود. میزان کشش در دیواره سرخرگ متناسب با ازدیاد قطر افزایش می یابد. اگر کار نگهدارندگی بافت های اطراف نبود، دیواره سرخرگ مانند تیوب دوچرخه، در شرایط همانند به طرف بیرون برجسته می شد. پارگی آنوریسم به ویژه اگر در مغز باشد، غالبا کشنده است. این پدیده در مغز یکی از علل حوادث عروق مغزی CVA است.
تشکیل پلاک های اسکلروتیک در دیواره سرخرگ ها، شایع تر از سایر بیماری های عروقی است. این پلاک ها با ایجاد جریان متلاطم، سوفل محسوسی تولید می کنند. کاهش قطر سرخرگ باعث افزایش سرعت خون در آن ناحیه می شود که به نوبه خود طبق قانون برنولی، فشار را در دیواره کاهش میدهد. گاهی پلاک یاد شده کند می شود و همراه با جریان خود حرکت می کند و سرانجام در سرخرگ کوچکی رسوب می کند. این گرفتگی جریان خون ناحیه را قطع می کند. اگر گرفتگی در مغز باشد، باعث سکته مغزی شده که نوع دیگری از عوارض رگ های مغزی است. یکی از بیماری هایی که از نظر بالینی به اندازه آنوریسم ها و پلاک ها خطر آفرین نیست، بلکه بیشتر باعث نگرانی بیمار می شود واریس است. سیاهرگ های واریسی افزون بر ایجاد عوارض ظاهری، عوارض دیگری نیز دارند. نارسایی دریچه های یک طرفه سیاهرگها باعث گشادی سیاهرگ های سطحی پا می شود. جریان خون را در بخش پایینی پاهای یک فرد ایستاده در نظر بگیرید. فشار در یک سیاهرگ پا نزدیک90 Torr است و این به علت ستون خون بالای آن است. هنگام راه رفتن یا سایر ورزش های پا، انقباض ماهیچه ها باعث حرکت خون سیاهرگی به طرف قلب می شود.
آناتومی و عمل قلب:
قلب ارگان حیاتی بدن و عنصر اصلی سیستم گردش خون در بدن می باشد. به عنوان یک پمپ چهارحفرهای برای گردش خون بدن، عمل می کند، می توان گفت قلب در اصل یک تلمبه دوگانه است و نیروی لازم برای حرکت خون در دو سیستم اصلی گردش خون، یعنی گردش خون ششی در شش ها و گردش خون عمومی در سایر نقاط بدن را فراهم می آورد. یکی قلب چپ که خون بازگشتی از ریه ها را به بافت ها می رساند (گردش خون بزرگ یا سیستمیک) و دیگری قلب راست که خون بازگشتی از بافت ها را به ریه ها می رساند (گردش خون کوچک یا ریوی) در یک فرد طبیعی، خون پس از گردش در یک سیستم توسط بخش دیگر قلب به سیستم دوم تلمبه می شود.
عمل پمپاژ اصلی توسط بطن ها انجام می شود و دهلیزها فقط پیش حفره هایی هستند تا خون را در طول زمانی که بطن ها عمل پمپ را انجام می دهند، ذخیره کنند. فاز استراحت یا پر شدن چرخه قلب، دیاستول نامیده می شود. فاز انقباض یا پر کردن سیستول نام دارد. خون قلب چپ که دارای اکسیژن است به داخل آئورت پمپاژ شده و از آنجا از طریق شریان و شریانچه ها به داخل مویرگ ها هدایت می شود. خون هنگام عبور از مویرگ های بافتی اکسیژن خود را از دست می دهد و به رنگ تیره در می آید. این خون تیره به قلب راست باز می گردد و بطن راست آن را از شریان های ریوی به ریه ها می فرستد و در ریه ها خون اکسیژن می گیرد و رنگش مجددا به قرمز روشن تبدیل می گردد و خون روشن توسط وریدهای ریوی به قلب چپ بر می گردد.
منشا فعالیت الکتریکی، انقباض صاف و منظم دهلیزها و بطن ها به شکل مجموعه ای هماهنگ از وقایع الکتریکی است که درون قلب رخ می دهد. این مجموعه از وقایع الکتریکی که مربوط به خود قلب است و به هنگام برداشته شدن قلب (به ویژه بطن های مهره داران خونسرد مانند قورباغه یا لاکپشت) از بدن و قرار دادن آن در محلول حاوی مواد غذایی مانند محلول گلوکز رینگر) به خوبی روشن می شود. قلب برای ساعات زیادی به ضربان ادامه می دهد. انقباض هماهنگ دهلیزها و بطن ها با الگوی خاصی، توسط فعالیت الکتریکی سیستم عضلانی این ساختارها تنظیم می شود. به علاوه، الگوی فعالیت الکتریکی در دیواره های دهلیزها و بطنها توسط رشته ای از وقایع هماهنگ در سیستم هدایت ویژه قلب شروع می شوند. سیستم هدایت ویژه در مقایسه با قلب به عنوان یک مجموعه کلی، خیلی کوچک است. این سیستم فقط یک بخش جزئی از جرم کل قلب را تشکیل می دهد. دیواره بطن چپ 5.0-2.3 برابر ضخامت دیواره بطن راست است و تیغه داخل بطنی تقریبا به ضخامت دیواره بطن چپ است. اگر قلب را به عنوان یک منبع بیوالکتریکی در نظر بگیریم، می توان انتظار داشت که استحکام این منبع مستقیما در ارتباط با جرم ماهیچه فعال (یعنی، به تعداد سلول های میوکاردیال فعال) باشد. بنابراین دهلیزها و دیواره های آزاد و تیغه بطن ها را می توان از عوامل عمده موثر بر میدان های پتانسیل خارجی قلب در نظر گرفت.
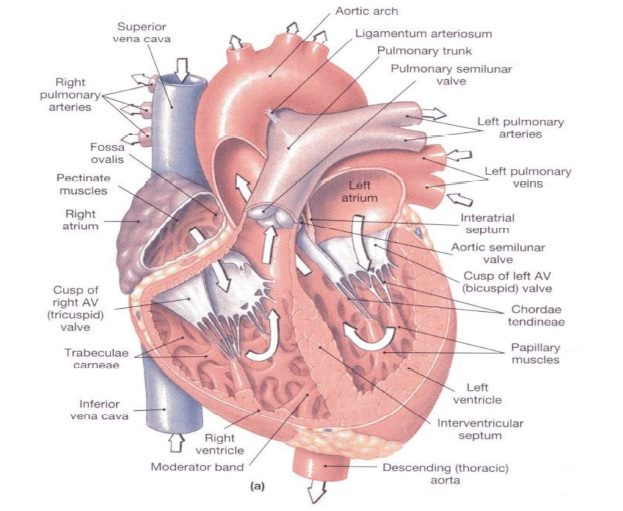
شکل آناتومی قلب.
عروق کرونری و بیماری های عروق کرونری:
به رگ هایی که به عضله های قلب خون رسانی می کنند، عروق کرونری می گویند. عروق کرونری به دو دسته کرونری راست و چپا تقسیم می شوند. این عروق مطابق شکل زیر در دو نوع سرخرگی و سیاهرگی عمل خون رسانی به ماهیچه های قلب را به عهده دارند.
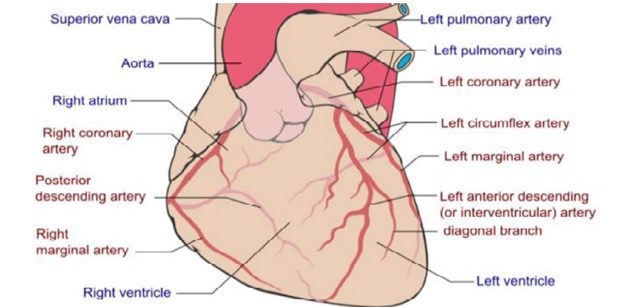
شکل ساختار عروق خونی کرونر قلب (عروق کرونری راست و چپ).
انسداد شریان (شکل زیر) یکی از عوامل اصلی بیماری عروق کرونر است. عامل انسداد شریان پلاک هایی در عروق کرونر هستند که باعث تنگی یا انسداد کامل عروق می شوند. از عوامل خطرساز که زمینه را برای ابتلا به بیماری عروق کرونری فراهم می کند می توان به فشار خون بالا، چربی خون بالا، سیگار کشیدن و عدم تحرک و ورزش نکردن اشاره داشت.

شکل انسداد شریان.
بیماری شریان کرونر یا بیماری عروق کرونر قلب، عارضه ای است که در آن پلاکی درون شریان های کرونر یا شریان های تغذیه کننده عضله قلب با خون اکسیژن دار ایجاد می شود. این پلاک از چربی، کلسترول، کلسیم و سایر مواد موجود در خون تشکیل می شود. هنگامی که این پلاک درون شریان ها تشکیل می شود، عارضه ایجاد شده را تصلب شرایین یا آتروسکلروز می گویند. پلاک باعث تنگ شدن شریان ها می شود و در نتیجه جریان خون رسانی به عضله قلب را کاهش می دهد. همچنین وجود این پلاک، احتمال ایجاد لخته خون را درون شریان افزایش میدهد. لخته های خون ممکن است به طور نسبی یا کامل جریان خون را مسدود کنند. هنگامی که شریان های کرونر قلب باریک با مسدود می شوند (شکل زیر)، خون اکسیژن دار نمی تواند به عضله قلب برسد، در نتیجه ممکن است آنژین صدری یا حمله قلبی رخ دهد. حمله قلبی بدون درمان سریع می تواند به عوارضی وخیم و حتی مرگ منجر شود. تشخیص به موقع انسداد شریان در عروق کرونر ضروری و مانع پیشرفت این بیماری می شود. همچنین با مصرف دارو یا انجام عمل آنژیوگرافی و آنژیوپلاستی و استفاده از جراحی بای پس می توان از بروز خطرات جدی در بیماران عروق کرونر جلوگیری کرد.
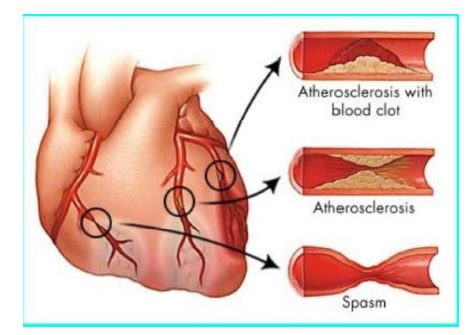
شکل انسداد رگ با (به ترتیب از بالا)، الف) پلاک و لخته خوتی، ب) پلاک، ج) تنگ شدگی.
شدت رقابت ها در عرصه های علمی، اجتماعی، اقتصادی، سیاسی و نظامی نیز اهمیت سرعت با زمان دسترسی به اطلاعات را دوچندان کرده است؛ بنابراین نیاز به طراحی سیستم هایی که قادر به اکتشاف سریع اطلاعات مورد علاقه کاربران با تأکید بر حداقل مداخله انسانی باشند. از یک سو و روی آوردن به روش های تحلیل متناسب با حجم داده های حجیم از سوی دیگر، به خوبی احساس می شود. در حال حاضر، داده کاوی مهم ترین فناوری برای بهره وری مؤثر، صحیح و سریع از داده های حجیم است و اهمیت آن رو به فزونی است داده کاوی پل ارتباطی میان علم آمار، علم کامپیوتر، هوش مصنوعی الگوشناسی، فراگیری ماشین است. داده کاوی فرآیندی پیچیده جهت شناسایی الگوها و مدل های صحیح، جدید و به صورت بالقوه مفید، در حجم وسیعی از داده است، به طریقی که این الگوها و مدل ها برای انسان ها قابل درک باشند. داده کاوی به صورت یک محصول قابل خریداری نیست، بلکه یک رشته علمی و فرآیندی است که بایستی به صورت یک پروژه پیاده سازی شود. داده ها اغلب حجیم می باشند و به تنهایی قابل استفاده نیستند، اما دانش نهفته در داده ها قابل استفاده است.
بنابراین بهره گیری از قدرت فرآیند داده کاوی جهت شناسایی الگوها و مدل ها و نیز ارتباط عناصر مختلف در پایگاه داده جهت کشف دانش نهفته در داده ها و نهایتا تبدیل داده به اطلاعات، روزبه روز ضروری تر می شود. در داده کاوی معمولا به کشف الگوهای مفید از میان داده ها اشاره می شود. منظور از الگوی مفید، مدلی در داده ها است که ارتباط میان یک زیر مجموعه از داده ها را توصیف می کند و معتبر، ساده، قابل فهم و جدید است.
بیماری گرفتگی عروق کرونری:
بیماری های قلبی عروقی در حال حاضر شایع ترین علل مرگ را در اکثر نقاط جهان و ایران تشکیل می دهند. شایع ترین بیماری قلبی، گرفتگی عروق کرونر می باشد که یکی از دلایل اصلی مرگ و میر جهان می باشد بطوری که حدودا یک سوم تمام مرگ ها در دنیا در اثر این عارضه رخ می دهد و تقریبا تمامی افراد مسن تا حدودی دارای اختلال گردش شریانی کرونر می باشند. از این رو تشخیص زودهنگام و پیشگیری به موقع از این بیماری از اهمیت فراوانی برخوردار می باشد. عروق کرونر رگ های خونی هستند که خون دارای اکسیژن را به عضله قلب حمل می کنند. به منظور پمپ کردن خون به سراسر بدن، قلب باید ذخیره دائمی از اکسیژن را داشته باشد. زمانی که خون از بطن چپ خارج می شود به سرخرگ اصلی بدن یعنی آئورت وارد می شود. در همان ابتدای سرخرگ آئورت، نزدیک به بالای قلب، دو سرخرگ کرونر منشعب شده است که تحت عنوان سرخرگ های کرونر چپ و راست شناخته می شوند. سرخرگ های کرونر در سطح قلب قرارگرفته و به شاخه های کوچکتر منشعب می شوند سپس به اعماق عضله قلب وارد شده و اکسیژن را به سلول های قلب می رسانند.
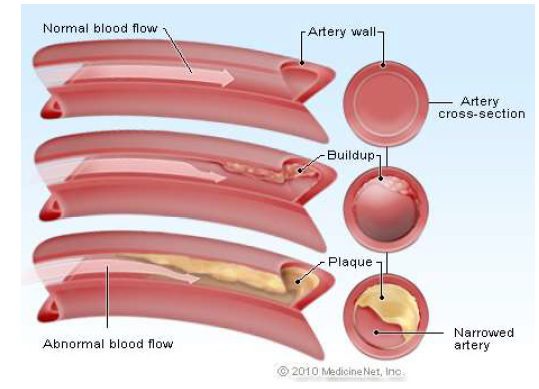
شکل مقایسه جریان خون نرمال و جریان خون غیرنرمال به دلیل تجمع چربی در رگ ها.
داخل دیواره سرخرگ ها به طور طبیعی صاف و انعطاف پذیر است که امکان حرکت جریان خون را به راحتی فراهم می کند. طی سال ها داخل دیواره رگ ممکن است با باقیمانده چربی ها پوشیده شود. زمانی که این روند (که آترواسکلروزیس نام دارد) دو سرخرگ کرونر را در بر گیرد، نتیجه بیماری عروق کرونر خواهد بود. ادامه تشکیل این رسوب باقیمانده های چربی که پلاک نام دارند در دیواره عروق ، باعث باریک تر شدن سرخرگ ها شده و جریان خون کاهش می یابد. این پلاک ها می توانند جریان خون سرخرگی را به حدی کاهش دهند که باعث آنژین یا حمله قلبی شوند. شکل فوق مقایسه جریان خون نرمال و جریان خون غیرنرمال را در رگ ها به دلیل تجمع چربی، نشان می دهد.آنژین به صورت درد و ناراحتی در قفسه سینه، بازو، گردن یا فک ظاهر می شود و زمانی روی می دهد که عروق کرونر مسدود شده اجازه عبور خون کافی را به عضله قلب نمی دهند. آنژین به طور مشخص طی فعالیت بدنی یا استرس روحی یعنی زمانی که قلب شدیدتر کار می کند و به اکسیژن بیشتری نیاز دارد، روی می دهد و تنها چند دقیقه طول می کشد و با استراحت فروکش می کند
در حمله قلبی، یک لخته خون معمولا در قسمت باریک رگی شکل می گیرد و راه عبور خون را مسدود می کند. این قطع جریان خون دارای اکسیژن به عضله قلب منجر به صدمه دائمی به بخشی از عضله قلب می شود.
برخلاف درد آنژین درد ناشی از حمله قلبی معمولا بیش از 15 دقیقه طول می کشد و با استراحت برطرف نمی شود. در حال حاضر مطمئن ترین روش و در واقع استاندارد طلایی جهت تشخیص گرفتگی در شریان های کرونری آنژیوگرافی است. در صورتی که فردی دچار آنژین صدری، درد در ناحیه قفسه سینه، تنگی آئورت یا نارسایی قلبی که علت آن مشخص نیست، شده باشد معمولا متخصص قلب انجام عمل آنژیوگرافی را به او توصیه می کند. به کمک آنژیوگرافی تعداد عروق کرونر مسدود شده، محل انسداد، و میزان آن مشخص می شود . آگاهی از این موارد به پزشک امکان می دهد نحوه درمان را تعیین کند. اما همانطور که میدانیم آنژیو گرافی یک روش تهاجمی بوده که علاوه بر هزینه و وقت گیر بودن منجر به خطراتی برای بیمار می گردد. از طرفی بسیاری از کسانی که آنژیوگرافی میشوند دارای گرفتگی عروق کرونر نیستند و در واقع نیازی به این عمل برای آنها نمی باشد. لذا عمل آنژیوگرافی برای این دسته از بیماران تنها خطرات ناشی از این روش هجومی و هزینه را در بر دارد. از طرف دیگر 25 درصد از افراد مبتلا به این بیماری بدون هیچ گونه علامت قبلی به صورت مرگ ناگهانی یا سکته حاد از دنیا می روند. بنابراین تصمیم گیری در مورد انجام شدن عمل آنژیوگرافی بسیار حائز اهمیت بوده و تا حد بسیار زیادی به تجربه پزشک معالج بستگی دارد که این تصمیم گیری را برای پزشک دشوار می سازد. بنابراین نیاز به روشی غیرتهاجمی است تا بتوان وجود CAD را در مراحل اولیه تشخیص داده و نسبت به درمان آن اقدام کرد.
در سالهای اخیر پژوهشگران زیادی تلاش نموده اند تا سیستم هایی ارائه دهند که در زمینه های مختلف، پزشکان را برای تشخیص هرچه سریع تر و دقیق تر یاری رسانند، به طوری که امروزه داده کاوی پزشکی یکی از شاخه های مهم در زمینه داده کاوی محسوب می گردد. حوزه کار داده کاوی پزشکی بسیار وسیع بوده و زمینه های مختلفی را در بر می گیرد. یکی از حوزه های مهم و پرکاربرد داده کاوی پزشکی، تشخیص بیماری می باشد. بیماری های قلبی عروقی نیز به عنوان یکی از شایع ترین و مهم ترین انواع بیماریها که بنا به گزارش انجمن قلب آمریکا یکی از پنج عامل اصلی مرگ در جهان است، در تحقیقات بسیاری موضوع کار پژوهشگران قرار گرفته است.
داده کاوی:
موضوع داده کاوی شناخت چیزهای جدید و با ارزش، بالقوه مفید، رابطه های منطقی و الگوهای موجود در داده ها است در جوامع مختلف یافتن الگو های مفید در داده ها با عناوین متعددی(مانند داده کاوی ) بیان می شود. برای مثال از عنوان هایی نظیر استخراج دانش، کشف اطلاعات، برداشت اطلاعات، پردازش الگوهای داده ها میتوان نام برد. توسط آمار شناسان، محققان پایگاه های داده ها و سیستم های اطلاعات مدیریتی داده کاوی عبارت و جوامع بازرگانی به کار برده می شود. عبارت کشف دانش در پایگاه داده ها عموماً برای اشاره به فرایند کلی کشف دانش مفید از داده هایی که داده کاوی گام مهمی در این فرایند است، مورد استفاده قرار می گیرد. گام های دیگری در فرایند کشف دانش در پایگاه داده ها نظیر آماده کردن داده ها، انتخاب داده ها، تمیز کردن داده ها و درک درست از فرایند داده کاوی موجب می شود تا اطلاعاتی که برای ما مفید هستند از داده ها استخراج شوند. داده کاوی از تحلیل های سنتی داده ها و رویکردهای آماری نشات گرفته است به طوری که شامل فنون تحلیلی ای است که از شاخه های دیگری تشکیل شده است، مانند :
-تحلیل های عددی
-الگوهای سازگار و سطوحی از هوش مصنوعی مانند یادگیری ماشین.
-شبکه های عصبی و الگوریتم های ژنتیک.
باوجود این بسیاری از داده کاوی ها بر روش های سنتی و رویکردهای تحلیل داده های مبتنی بر فرضیه تکیه دارد. اساساً دو رویکرد برای داده کاوی وجود دارد که از لحاظ ایجاد و طراحی مدل و یافتن الگوها با هم فرق دارند اولین رویکرد که مربوط به ساخت مدل است(جدا از مشکلاتی که ذاتا در مجموعه داده های بزرگ وجود دارد) مشابه روش های کاوشگرانه آماری مرسوم است. در این حالت هدف این است تا خلاصه های کلی از مجموعه ای از داده ها برای شناخت و توضیح خصوصیت های اصلی شکل توزیع به دست آوریم. مثال هایی از این قبیل مدل ها شامل تحلیل خوش های بخشی از مجموعه داده ها مدل رگرسیونی برای پیشگویی و قاعده رده بندی با ساختار درختی است.
نوع دوم رویکرد داده کاوی، رویکرد تشخیص الگو است. این رویکرد سعی بر آن دارد تا انحراف هایی هرچند کوچک از حد مطلوب(را تشخیص دهد) که در هر صورت حائز اهمیت هستند، تا الگوها و روندهای غیر معمول نمایان شود(مثال هایی نظیر الگو های نامعمول) برای تشخیص کلاهبرداری(در استفاده از کارت های اعتباری و موضوعاتی که الگوهایی با ویژگی های نا مشابه با سایر الگو ها دارند از این نوع کاربد است. این دسته از راهبردها است که موجب می شود تا داده کاوی به عنوان علم جستجوی اطلاعات با ارزش از بین توده عظیمی از داده ها به حساب آید. به طور کلی در پایگاه های داده ای کسب و کار ) تجاری ضعف در الگو ها به خاطر پیچیدگی زیاد آن هاست. این پیچیدگی ها در اثر ناپیوسته بودن، نامفهوم بودن و کامل نبودن به وجود می آیند. هرچند اکثر الگوریتم های داده کاوی می توانند اثر این گونه خصوصیت های نامربوط برا در تشخیص الگوی اصلی تمیز دهند، ولی قدرت پیش گویی الگوریتم های داده کاوی با افزایش این انحراف ها کاهش می یابد.
تعاریف داده کاوی:
نگاهی به ترجمه لغوی داده کاوی به ما در درک بهتر این واژه کمک می کند. واژة لاتین استخراج از منابع نهفته و با ارزش زمین اطلاق می شود. ادغام این کلمه با داده بر جستجویی عمیق از داده های قابل دسترس با حجم زیاد برای یافتن اطلاعات مفید که قبلا نهفته بودند، تاکید دارد داده کای دارای تعریف های مختلفی است این تعریف ها به مقدار زیادی به پیش زمینه ها و نقطه نظرهای افراد بستگی دارد. هر نویسنده، محقق و کابر با توجه به پیش زمینه ها و نقطه نظر های افراد بستگی دارد. هر نویسنده، محقق و کاربر با توجه به دیدگاه و نوع نگرش خود تعریف های مختلفی از داده کاوی ارائه کرده اند به عنوان مثال می توان به چند تعریف داده کاوی که در ادامه آمده است اشاره کرد:
-داده کاوی استخراج اطلاعات مفهومی، ناشناخته و به صورت بالقوه مفید از پایگاه داده میباشد
-داده کاوی علم استخراج اطلاعات مفید از پایگاه های داده یا مجموعه داده ای می باشد.
-داده کاوی استخراج نیمه اتوماتیک الگوها، تغییرات، وابستگی ها، نابهنجاری ها و دیگر ساختارهای معنی دار آماری از پایگاه های بزرگ داده می باشد.
-داده کاوی عبارت است از فرآیند استخراج اطلاعات معتبر، از پیش ناشناخته، قابل فهم و قابل اعتماد از پایگاه داده های بزرگ و استفاده از آن در تصمیم گیری در فعالیت های تجاری مهم.
-اصطلاح داده کاوی به فرایند نیم خودکار تجزیه و تحلیل پایگاه داده های بزرگ به منظور یافتن الگوهای مفید اطلاق می شود.
-داده کاوی یعنی جستجو در یک پایگاه داده ها برای یافتن الگوهایی میان داده ها.
باتوجه به اینکه بیماری گرفتگی شریان های کرونر، شایع ترین بیماری قلبی بوده و مرگ و میر بسیاری را سالانه به خود اختصاص می دهد. لذا در بین سایر بیماری های قلبی، بیشترین آمار به کار گیری داده کاوی پزشکی را به خود اختصاص می دهد. عموما تحقیقات به صورت مجزا و با مجموعه داده های متنوع که از روش های مختلف غیرتهاجمی به دست آمده اند، انجام شده است. محققان تاکنون الگوریتم های متعددی را در مقالات خود برای تشخیص بیماری گرفتگی کرونری ارائه نموده اند. بسیاری از مطالعات بر اساس ترکیبی از داده های استخراج شده از تست ها و آزمایشات مختلف، سعی در تشخیص گرفتگی شریان های کرونری نموده اند. به عنوان مثال می توان به استفاده از مجموعه داده کلیولند(Cleveland) نام برد. این مجموعه داده شامل مواردی از قبیل سن، جنسیت، میزان درد قفسه سینه، فشار خون، میزان کلسترول خون، اطلاعات مربوط به بخش ST (قسمتی از نوار قلب) و… می باشد.
دنیای مدرن در حقیقت دنیای داده گرا می باشد و ما در محاصره ی داده ها، چه عددی و چه انواع دیگر قرار گرفته ایم. پیشرفت شگفت انگیز فناوری های رایانه ای و مجهزشدن به این ابزار امکان جمع آوری اطلاعات دقیق و کامل در زمینه های مختلف را فراهم ساخته است و منجر به پیدایش ساختارهای داده بسیار حجیم شده است. همچنین حجم بسیار عظیمی از داده های موجود در پایگاه داده ی شرکت ها، دانشگاه ها، مراکز دولتی و سایر موسسات بدون استفاده مانده است. دستیابی به اطلاعات نهفته در این داده ها مستلزم مدیریت کاراست و با به کار بردن سیستم های سنتی این امر تحقق نمی یابد. شدت رقابت ها در عرصه های علمی، اجتماعی، اقتصادی، سیاسی و حتى نظامی نیز اهمیت عامل سرعت با زمان دسترسی به اطلاعات را دو چندان کرده است. بنابراین نیاز به طراحی سیستم هایی که قادر به اکتشاف سریع اطلاعات مورد علاقه ی کاربران با تاکید بر حداقل مداخله انسانی به خوبی احساس می شود.
داده کاوی فرآیندی است که در آغاز دهه ۹۰ پا به عرصه ظهور گذاشته و با نگرشی نو به مسئله استخراج اطلاعات از پایگاه داده می نگرد. این فرآیند یک مرحله فراتر از بازیابی ساده داده ها است و به کاربران اجازه می دهد که دانش جدید را در داده ها کشف کنند. داده کاوی یک علم میان رشته ای است و ترکیبی از علومی نظیر هوش مصنوعی، تحلیل آمار، بینایی ماشین و پایگاه داده است. به طور کلی داده کاوی به استخراج دانش از پایگاه های داده ی بزرگی اشاره دارد. داده کاوی به عنوان یک مرحله ضروری از فرآیند بزرگتر استخراج دانش است که شامل مراحل زیر است:
١- پاک سازی داده ها: حذف داده های ناایستا و مزاحم.
۲- یکپارچه سازی داده ها به ترکیب منابع داده متعدد، پراکنده و ناهمگن
۳- انتخاب ویژگی : انتخاب ویژگی های مهمی از داده ها. – تبدیل داده ها: تبدیل یا ترکیب داده ها به اشکالی مناسب برای به کار بردن روش های مختلف آماری
5- داده کاوی: مرحله ای ضروری از فرآیند استخراج دانش است که در آن از روش های مختلف آماری برای استخراج الگوها استفاده می شود.
6- ارزیابی الگوها: شناسایی الگوهای جذاب ارائه دانش بر اساس معیارهای جذابیت.
۷- ارائه دانش: ارائه دانش استخراج شده با استفاده از تکنیک های نمایش اطلاعات.
شکل زیر مراحل فرآیند اکتشاف دانش از پایگاه های داده را نشان می دهد.
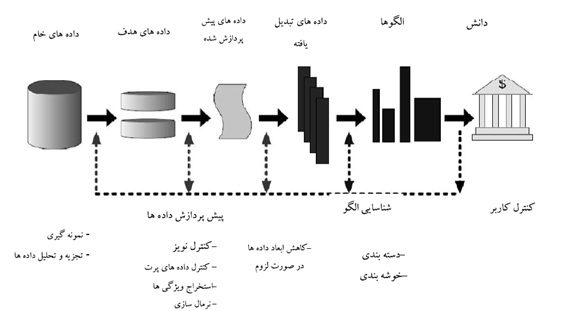
شکل فرآیند داده کاوی.
با اینکه اختلاف نظرهایی درباره تعریف دقیق داده کاوی وجود دارد، متخصصین و صاحب نظران بر این باورند که داده کاری یک گرایش چند منظوره می باشد که مفاهیمی از یادگیری ماشین، هوش مصنوعی، آمار، محاسبات با کارایی بالا، پردازش سیگنال و تصویر، بهینه سازی ریاضی، تشخیص الگو را در بردارد. آنچه که تازه است، ترکیب و تلفیق این تکنولوژی ها به منظور تحلیل مجموعه داده های بزرگ می باشد. با کاربرد یافتن داده کاوی در مسائل و حوزه های جدید، پیچیدگی آن نیز رشد می یابد. به عنوان مثال، رشد و توسعه اینترنت و وب گسترده جهانی باعث ایجاد وظایفی نظیر خوشه بندی مستندات متنی، جستجوهای چندرسانه ای و کاوش الگوهای کاربران وب به منظور پیش بینی گشت و گذارهای آینده کاربران و یافتن محل های مناسب برای تبلیغات شده است.
داده کاوی کاربردهای فراوانی در زمینه های مختلف دارد. بعضی از این کاربردها عبارتند از:
– کاربردهای معمول تجاری: تحلیل و مدیریت بازار، تحلیل سبد خرید، بازاریابی هدف، درک رفتار مشتری، تحلیل و مدیریت ریسک، تحلیل قابلیت رقابل و کنترل کیفیت
– مدیریت و کشف فریب: کشف فریب تلفنی، کشف تقلب های بیمه ای، کشف تراکنش های مشکوک مالی نظیر پولشویی.
– متن کاوی: پالایش متن نظیر پست الکترونیکی، مستندات و گروه های خبری – پزشکی: کشف ارتباط علائم و بیماری، تحلیل DNA و داده های زیستی، تصاویر پزشکی
– ورزش: آمارهای ورزشی
– وب کاوی: پیشنهاد صفحات مرتبط و بهبود ماشین های جستجوگر.
این فرآیند در شرایطی مورد استفاده قرار می گیرد که داده ها بسیار زیاد یا پیچیده باشند و تحلیل دستی و به کمک پرس و جوهای ساده پاسخگو نباشد. داده کاوی از دو مرحله اصلی تشکیل شده است؛ مرحله اول پیش پردازش داده ها است که در طول این مرحله، خصیصه ها یا صفات مرتبه بالا از داده های سطح پایین استخراج می شوند. مرحله دوم تشخیص الگو می باشد که در این مرحله الگوی موجود در داده ها به کمک خصیصه ها و صفات به دست آمده از مرحله اول، تشخیص داده می شوند. به صورت کلی روش های داده کاوی به دو گروه با نظارت و بدون نظارت تقسیم بندی می شوند. در روش های بدون نظارت متغیر هدفی تعریف نمی شود و الگوریتم داده کاوی همبستگی ها و ساختارهای بین تمام متغیرها را جستجو می کند. از مهم ترین روش های داده کاوی بدون نظارت، خوشه بندی را می توان نام برد. اکثر روش های داده کاوی روش های بأنظارت می باشند که در این روش ها یک متغیر هدف از قبل تعریف شده وجود دارد. در این روش ها مثال های زیادی وجود دارند که مقدار متغیر هدف برای آنها مشخص می باشد، بنابراین الگوریتم می تواند به کمک آنها آموزش ببیند که کدام متغیر هدف با کدام مقادیر متغیرهای پیش بینی کننده، متناظر می باشد.
دسته بندی یکی از مطرح ترین روش های با نظارت است. این عمل از مهم ترین کارهایی است که انسان به صورت روزمره انجام می دهد. در دسته بندی یک متغیر هدف، گروهی وجود دارد که به دسته ها و گروه های از قبل تعیین شده افراز میگردد. مدل داده کاوی مجموعه گسترده ای از رکوردها را مورد بررسی قرار می دهد و به کمک آن مجموعه آموزشی ایجاد می گردد. سپس این مدل توسط یک مجموعه آزمایشی مورد ارزیابی قرار گرفته و تنظیم می شود و در نهایت مدل نهایی به دست می آید. اولین قدم در فرآیند دسته بندی، جمع آوری داده ها می باشد. با استفاده از فرد خبره می توان تعداد صفت ها و تعداد نمونه های مورد نیاز را جمع آوری کرد. در غیر این صورت، ساده ترین راه، جمع آوری کلیه صفات و نمونه های ممکن به صورت کورکورانه می باشد. البته داده هایی که به این صورت به دست آیند معمولا دارای داده های پرتا، نویز و صفات بدون مقدار هستند و نیاز به پیش پردازش زمان بری دارند. دومین مرحله، پاک سازی و آماده سازی داده ها برای پردازش است. در گام بعدی، داده های پاک سازی شده به دو مجموعه آموزش و آزمون افراز می شوند که از داده های آموزش برای ایجاد کردن دسته بند و داده های آزمون برای ارزیابی کارایی دسته بند استفاده می شود.
الگوریتم های مختلفی برای عمل دسته بندی ارائه شده اند که از مهم ترین آنها می توان به رگرسیون خطی، درخت تصمیم و قوانین، شبکه های عصبی، روش های فرااکتشافی، سیستم های فازی و SVM اشاره کرد. پس از انتخاب الگوریتم دسته بندی، اکنون یک دسته بند با استفاده از نمونه های آموزش ساخته می شود. نحوه انتخاب پارامترهای دسته بندی اثر مستقیمی بر کارایی الگوریتم های دسته بندی دارد؛ بنابراین باید مقدار پارامترهای الگوریتم دسته بندی به درستی تنظیم شوند. در نهایت کارایی الگوریتم دسته بند با استفاده از داده های آزمایشی ارزیابی می شود.
تکنیک ماشین بردار پشتیبان(SVM):
این روش توسط واپینگ معرفی شد و بر مبنای دسته بندی خطی داده ها است. این روش که نام دیگر آن SVM می باشد با ساخت یک معادله خطی یا فوق صفحه، داده ها را از هم جدا می کند به طوریکه داده های موجود در یک دسته بیشترین شباهت را با هم دارند و داده های درون دسته های مختلف دارای کمترین شباهت هستند. الگوریتم ماشین بردار پشتیبان یکی از دقیق ترین روش ها و بر پایه یادگیری ماشین است که پایه نظری دارد و به تعداد ابعاد حساس نمی باشد. در موضوعات یادگیری دو دسته ای هدف این الگوریتم یافتن بهترین تابع دسته بندی برای تمایز مابین اعضای دو دسته در داده های آموزشی می باشد. این الگوریتم ضمانت می کند که بهترین تابع را با ماکزیمم حاشیه بین دو دسته پیدا کند. ماشین بردار پشتیبان دسته بندی کننده ای است که جزو شاخه متدهای هسته ۱۰ در یادگیری ماشین محسوب می شود و برای داده های گسسته استفاده می شود.
SVM در سال ۱۹۹۲ توسط وپنیک ۱۱ معرفی شده و بر پایه تئوری های آماری بنا گردیده است. هدف این دسته الگوریتم ها تشخیص و متمایز کردن الگوهای پیچیده در داده ها است. در این روش با فرض اینکه دسته ها بصورت خطی جداپذیر باشند، ابر صفحه هائی با حداکثر حاشیه بدست می آید که دسته ها را جدا کند. در مسایلی که داده ها بصورت خطی جداپذیر نباشند داده ها به فضای با ابعاد بیشتر نگاشت پیدا می کنند تا بتوان آنها را در این فضای جدید بصورت خطی جدا نمود.
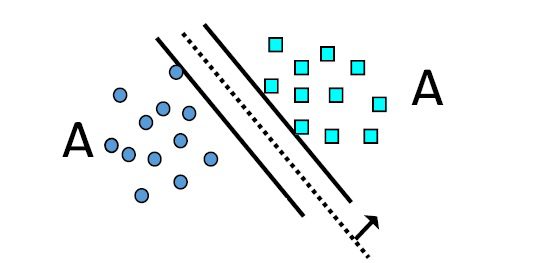
شکل ماشین بردار پشتیبان.
همانطور که در شکل فوق دیده می شود، هدف در این الگوریتم پیدا کردن بهترین خط( ابر صفحه) که دو دسته را از هم جدا کند. در حالت دو بعدی معادله این خط بصورت زیر است:

در حالت n بعدی خواهیم داشت
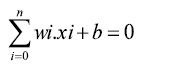
نزدیکترین داده های آموزشی به ابر صفحه های جدا کننده بردار پشتیبان نامیده می شوند. این موضوع در شکل زیر نمایش داده شده است.
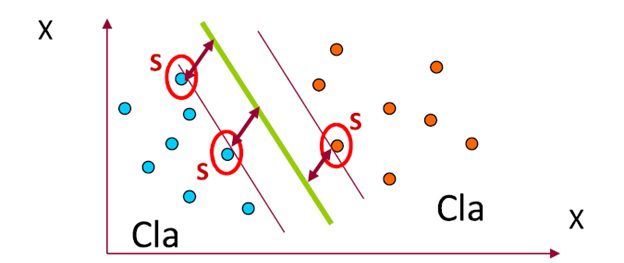
شکل بردار پشتیبان.
مزایای این الگوریتم عبارتست از:
-علیرغم داشتن ابعاد زیاد از سرریز پرهیز میکند. این خاصیت ناشی از بهبود این الگوریتم است.
-فشرده سازی اطلاعات زیرا بجای داده های آموزشی از بردارهای پشتیبان استفاده می کند.
در حقیقت این الگوریتم به روش زیر داده ها را در دو دسته قرار می دهد.

معادلات فوق در شکل زیر نمایش داده شده است.

شکل صفحات در ماشین بردار پشتیبان.
تبدیل داده به فضای ویژگی در شکل زیر نشان داده شده است.
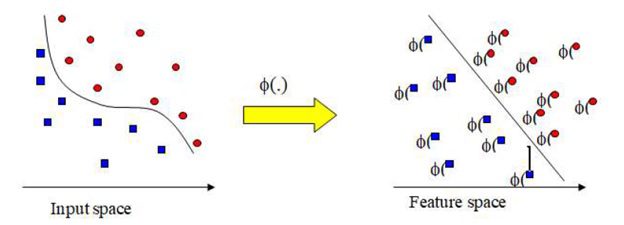
شکل تبدیل داده به فضای ویژگی.
ماشین های بردار پشتیبان(SVM) مدل های یادگیری با ناظر هستند که الگوریتم های یادگیری همراه شده با آنها، برای اهداف طبقه بندی و تحلیل رگرسیون، دادگان را کاوش و الگوها را بازشناسی می نمایند. برای یک مجموعه از نمونه های آموزشی که مشخص شده است هرکدام به چه کلاسی از دو کلاس موجود متعلق هستند، یک الگوریتم آموزشی SVM مدلی را می سازد که الگوهای جدید را به کلاس اول یا دوم منتسب می نماید. این مساله، SVM را مبدل به یک طبقه بندی خطی باینری غیر احتمالاتی می نماید. یک مدل SVM نمونه ها را به صورت نقاطی در فضا نمایش می دهد و آنها را طوری نگاشت می کند که نمونه های متعلق به هر کلاس توسط یک حاشیة مشخص که تا جای ممکن عریض است، از یکدیگر جدا باشند. پس از آن الگوهای جدید در همان فضا نگاشت گردیده و بر این اساس که در کدام طرف آن حاشیه قرار گرفته اند، کلاس متعلق به آنها پیش بینی می شود. زیربنای نظری رویکرد ماشین بردار پشتیبان به گونه ای است که برای مجموعه داده های کوچک عملکرد خوبی دارد و نسبت به تعداد ابعاد داده حساس نیست. SVM یکی از نقاط اشتراک تحقیق در عملیات و داده کاوی است زیرا روش SVM همواره مساله را به صورت یک مساله برنامه ریزی ریاضی مدل سازی می کند و به وسیلة حل این مدل، به ارائه جواب می پردازد. در این روش همواره هدف، یافتن یک یا چند ابر صفحه برای جدا کردن داده ها از یکدیگر می باشد. باید اشاره کرد که ممکن است برخی از مجموعه داده ها را نتوان با ابرصفحه ها از یکدیگر جداسازی کرد. در اینگونه موارد میتوان برای جداسازی کامل داده ها از منحنی ها و یا توابع غیرخطی استفاده کرد. اما به هرحال در این وضعیت نیز می توان با پذیرفتن خطای دسته بندی، داده ها را بوسیله ابر صفحه ها از یکدیگر جدا کرد. ابر صفحه بدست آمده برای جداسازی دسته ها به عنوان یک معیار در نظر گرفته می شود. به این ترتیب که به کمک آن می توان وضعیت داده هایی که وضعیت آنها مشخص نیست را تعیین کرد. درواقع در دسته بندی داده ها ارائه یک مدل بوسیله داده هایی که کلاس آنها مشخص است مدنظر گرفته می شود، تا به کمک آن داده هایی را که کلاس آنها معلوم نیست به یکی از دسته ها نسبت داده شوند. هر ابر صفحه ممکن است برای پیش بینی دسته ها مورد قبول نباشد. از هر مجموعه داده تعدادی برای بدست آوردن ابر صفحه مناسب و تعدادی برای آزمون کردن دقت ابر صفحه بدست آمده در جداسازی داده ها استفاده می شوند. اگر دقت در حد قابل قبولی بود از آن ابر صفحه استفاده می شود. در غیر اینصورت برای یافتن یک ابر صفحه دیگر با دقت بالاتر تلاش مجددی صورت می گیرد. این الگوریتم ها علاوه بر طبقه بندی، همچنین می توانند در حوزه تخمین نیز استفاده شوند. در نتیجه، به جرات می توان گفت که SVM از دقیق ترین و نیرومندترین الگوریتم های داده کاوی بشمار می رود. این شیوه برای طبقه بندی داده های خطی و غیرخطی مناسب است. SVM به محاسبات پیچیده ای نیاز دارد و به همین دلیل سریع ترین آنها بسیار کند عمل میکند. پیچیدگی محاسباتی این الگوریتم ها به فضای ورودی بستگی ندارد و نتیجه نهایی از دقت بسیار بالایی برخوردار است. این الگوریتم ها به طور خودکار اندازه مدل را انتخاب می کنند.
شبکه های بیزین:
این روش از قانون بیز و احتمالات شرطی استفاده می کند. در این روش باید احتمال تمام کلاس ها به شرط یک نمونه جدید محاسبه شود و سپس کلاسی که احتمال حداکثر دارد انتخاب می شود.
رگرسیون لجستیک:
در این روش تمامی عوامل پیش بینی کننده همزمان مورد توجه قرار می گیرد و به جای پیش گویی احتمال رخداد آن محاسبه می شود. مفهوم نسبت برتری در این روش استفاده می گردد.
درخت تصمیم(decision tree):
درخت تصمیم درختی است که در آن نمونه ها را به نحوی دسته بندی می کند که از ریشه به سمت پائین رشد می کنند و در نهایت به گره های برگ می رسد. هر گره داخلی یا غیر برگ با یک ویژگی مشخص می شود، این ویژگی سوالی را در رابطه با مثال ورودی مطرح می کند. در هر گره داخلی به تعداد جواب های ممکن با این سوال شاخه وجود دارد که هر یک با مقدار آن جواب مشخص می شود. برگ های این درخت با یک کلاس و یا یک دسته از جواب ها مشخص می شوند. علت نامگذاری آن با درخت تصمیم این است که این درخت فرآیند تصمیم گیری برای تعیین دسته یک مثال ورودی را نشان می دهد. ساختار درخت تصمیم در یادگیری ماشین، یک مدل پیش بینی کننده می باشد که حقایق مشاهده شده در مورد یک پدیده را به استنتاج هایی در مورد مقدار هدف آن پدیده نقش می کند. تکنیک یادگیری ماشین برای استنتاج یک درخت تصمیم از داده ها، یادگیری درخت تصمیم نامیده می شود که یکی از رایج ترین روش های داده کاوی است. هر گره داخلی متناظر یک متغیر و هر کمان به یک فرزند، نمایانگر یک مقدار ممکن برای آن متغیر است. یک گره برگ، با داشتن مقادیر متغیرها که با مسیری از ریشه درخت تا آن گرهء برگ بازنمایی می شود، مقدار پیش بینی شده، متغیر هدف را نشان می دهد. یک درخت تصمیم ساختاری را نشان می دهد که برگ ها نشان دهنده دسته بندی و شاخه ها ترکیبات فصلی صفاتی که منتج به این دسته بندی ها را بازنمایی می کنند. یادگیری یک درخت می تواند با تفکیک کردن یک مجموعه منبع به زیرمجموعه هایی براساس یک تست مقدار صفت انجام شود. این فرآیند به شکل بازگشتی در هر زیر مجموعهء حاصل از تفکیک تکرار می شود. عمل بازگشت زمانی کامل می شود که تفکیک بیشتر سودمند نباشد یا بتوان یک دسته بندی را به همهء نمونه های موجود در زیر مجموعهء بدست آمده اعمال کرد. درختان تصمیم قادر به تولید توصیفات قابل درک برای انسان، از روابط موجود در یک مجموعهء داده ای هستند و می توانند برای وظایف دسته بندی و پیش بینی بکار روند. این تکنیک به شکل گسترده ای در زمینه های مختلف همچون تشخیص بیماری دسته بندی گیاهان و استراتژی های بازاریابی مشتری بکار رفته است. این ساختار تصمیم گیری می تواند به شکل تکنیک های ریاضی و محاسباتی که به توصیف، دسته بندی و عام سازی یک مجموعه از داده ها کمک می کنند نیز معرفی شوند. داده ها در رکوردهایی به شکل (x,y)=(x1, x2, x3, …,xk, y) داده می شوند. با استفاده از متغیرهای x1, x2, …,xk سعی در درک، دسته بندی یا عام سازی متغیر وابستهء Y داریم. انواع صفات در درخت تصمیم به دو نوع صفات دسته ای و صفات حقیقی بوده که صفات دسته ای، صفاتی هستند که دو یا چند مقدار گسسته می پذیرند (یا صفات سمبلیک) در حالی که صفات حقیقی مقادیر خود را از مجموعهء اعداد حقیقی می گیرند.
اهداف اصلی درخت های تصمیم گیری دسته بندی کننده:
-داده های ورودی را تا حد ممکن درست دسته بندی کنند.
-دانش یادگیری شده از داده های آموزشی را به گونه ای عام سازی کنند که داده های دیده نشده را با بالاترین دقت ممکن دسته بندی کنند.
-در صورت اضافه شدن داده های آموزشی جدید، بتوان به راحتی درخت تصمیم گیری را گسترش داد (دارای خاصیت افزایشی باشند).
-ساختار درخت حاصل به ساده ترین شکل ممکن باشد.
گام های لازم برای طراحی یک درخت تصمیم گیری:
-انتخاب مناسبی برای ساختار درخت.
-انتخاب ویژگی هایی مورد نظر برای تصمیم گیری در هر یک از گره های میانی.
-انتخاب قانون تصمیم گیری با استراتژی مورد استفاده در هر یک از گره های میانی
جذابیت درختان تصمیم:
نواحی تصمیم پیچیدهء سراسری (خصوصا در فضاهای با ابعاد زیاد) می توانند با اجتماع نواحی تصمیم محلی ساده تر در سطوح مختلف درخت تقریب زده شوند. برخلاف دسته بندی کننده های تک مرحله ای رایج که هر نمونهء داده ای روی تمام دسته ها امتحان می شود، در یک دسته بندی کنندهء درخت، یک نمونه فقط روی زیرمجموعه های خاصی از دسته ها امتحان شده و محاسبات غیرلازم حذف می شود. در دسته بندی کننده های تک مرحله ای، فقط از زیر مجموعه ای از صفات، برای تفکیک بین دسته ها استفاده می شود که معمولا با یک معیار بهینهء سراسری انتخاب می شوند. در دسته بندی کننده درخت، انعطاف پذیری انتخاب زیر مجموعه های مختلفی از صفات در گره های داخلی مختلف درخت وجود دارد؛ به شکلی که زیرمجموعهء انتخاب شده به شکل بهینه بین دسته های این گره را تفکیک می کند. این انعطاف پذیری ممکن است بهبودی در کارایی را نسبت به دسته بندی کننده های تک مرحله ای ایجاد کند.
در تحلیل چندگونگی با تعداد صفات و دسته های زیاد، معمولا نیاز به تخمین توزیع های ابعاد-زیاد یا پارامترهای خاصی از توزیع های دسته همانند احتمالات اولیه از یک مجموعهء داده های آموزشی کوچک می باشد. در این حالت مشکل ابعاد-بالا وجود دارد که امکان دارد در درخت دسته بندی کننده، با بکاربردن تعداد کمتری از صفات در هر گرهء داخلی بدون افت شدید کارایی، این مسئله حل شود.
عام سازی درخت:
در ساخت درخت دو انتخاب وجود دارد:
۱) طراحی درختی که تمام نمونه های آموزشی را به شکل صحیح دسته بندی کند(درخت کامل) و انتخاب کوچکترین درخت
۲) ساخت درختی که کامل نبوده اما کمترین نرخ خطای ممکن در دسته بندی نمونه های تست را دارد (در عمل این روش مطلوب تر است. در هر دو حالت کوچک نگاه داشتن اندازهء درخت تاحد امکان مطلوب است. دلایل آن این است که درختان کوچکتر زمان تست و نیاز حافظهء کمتری داشته و تمایل به عام سازی بهتر نمونه های نادیده دارند (چون به بی قاعدگی های آماری و طبیعت داده های آموزشی کمتر حساس هستند).
مزایای درختان تصمیم نسبت به روش های دیگر داده کاوی:
-قوانین تولید شده و به کارگرفته شده قابل استخراج و قابل فهم می باشند.
-درخت تصمیم، توانایی کار با داده های پیوسته و گسسته را دارد. (روشهای دیگر فقط توان کار با یک نوع را دارند. مثلا شبکه های عصبی فقط توان کار با داده های پیوسته و قوانین رابطه با داده های گسسته)
-درخت تصمیم از نواحی تصمیم گیری ساده استفاده می کند.
-مقایسه های غیرضروری در این ساختار حذف می شود.
-از ویژگی های متفاوت برای نمونه های مختلف استفاده می شود.
-احتیاجی به تخمین تابع توزیع نیست.
-آماده سازی داده ها برای یک درخت تصمیم، ساده یا غیر ضروری است. روش های دیگر اغلب نیاز به نرمال سازی داده یا حذف مقادیر خالی یا ایجاد متغیرهای پوچ دارند).
-درخت تصمیم یک مدل جعبهء سفید است. توصیف شرایط در درختان تصمیم به آسانی با منطق بولی امکان پذیر است در حالی که شبکه های عصبی بدلیل پیچیدگی در توصیف نتایج آنها یک جعبهء سیاه می باشند.
-تایید یک مدل در درخت های تصمیم با استفاده از تست های آماری امکان پذیر است. (قابلیت اطمینان مدل را می توان نشان داد)
-ساختارهای درخت تصمیم برای تحلیل داده های بزرگ در زمان کوتاه قدرتمند می باشند.
-روابط غیرمنتظره یا نامعلوم را می یابند.
-درخت های تصمیم قادر به شناسایی تفاوت های زیر گروه ها می باشند.
-درخت های تصمیم قادر به سازگار کردن داده های فاقد مقدار می باشند.
معایب درختان تصمیم:
-در مواردی که هدف از یادگیری، تخمین تابعی با مقادیر پیوسته است مناسب نیستند. .
-در موارد با تعداد دسته های زیاد و نمونهء آموزشی کم، احتمال خطا بالاست.
-تولید درخت تصمیم گیری، هزینه محاسباتی بالا دارد.
-هرس کردن درخت هزینه بالایی دارد.
-در مسائلی که دسته های ورودی با نواحی مکعبی به خوبی جدا نشوند و دسته ها همپوشانی داشته باشند، خوب عمل نمی کنند.
-در صورت همپوشانی گره ها تعداد گره های پایانی زیاد می شود.
-در صورتی که درخت بزرگ باشد امکان است خطاها از سطحی به سطحی دیگر جمع شوند(انباشته شدن خطای لایه ها بر روی یکدیگر).
-طراحی درخت تصمیم گیری بهینه، دشوار است. کارایی یک درخت دسته بندی کننده به چگونگی طراحی خوب آن بستگی دارد.
-احتمال تولید روابط نادرست وجود دارد.
-بازنمایی درخت تصمیم دشوار است.
-وقتی تعداد دسته ها زیاد است، می تواند باعث شود که تعداد گره های پایانی بیشتر از تعداد دسته های واقعی بوده و بنابراین زمان جستجو و فضای حافظه را افزایش می دهد.
انواع درختان تصمیم:
درختان رگرسیون:
وظیفه یادگیری در درختان رگرسیون، شامل پیش بینی اعداد حقیقی بجای مقادیر دسته ای گسسته است. که این عمل را با داشتن مقادیر حقیقی در گره های برگ خود نشان می دهند. بدین صورت که میانگین مقادیر هدف نمونه های آموزشی را در این گرهء برگ بدست می آورند. این نوع از درختان، تفسیر آسان داشته و می توانند توابع ثابت تکه ای را تقریب بزنند.
نسخه پیچیده تر درختان رگراسیون، درختان مدل هستند که عمل رگراسیون را با داشتن مدل خطی در گره های داخلی یا پایانی نشان می دهند در هر گره، توابع رگراسیون خطی دارند). بعد از اینکه درخت رگراسیون کامل ساخته شد، عمل رگراسیون خطی، به نمونه هایی که به این گره رسیده اند اعمال می شود و فقط از یک زیرمجموعه از صفات (صفاتی که در زیر درخت دیده خواهند شد برای این کار استفاده می شوند. بدلیل استفاده از زیر مجموعه ای از صفات در هر گره، سربار عمل رگراسیون خطی زیاد نخواهد شد.
الگوریتم id3:
این الگوریتم درختان تصمیم از بالا به پایین می سازد و با طرح این سوال که چه صفتی باید در ریشه درخت آزمایش شود آغاز می کند. برای پاسخ به این سوال، با استفاده از یکی از انواع آزمایش های آماری برای تعیین مناسب ترین صفت برای دسته بندی مثال های آموزشی، تصمیم براساس هر صفت نمونه ر ارزیابی می کند. سپس بهترین صفت را انتخاب کرده و به عنوان تست در گرهء ریشهء درخت استفاده می کند. برای هر مقدار ممکن صفت تست شده در ریشه، یک گرهء متناظر ایجاد شده و مثال های آموزشی براساس مقادیر صفت تست، بین این گره ها افراز می شوند. تمام فرایند ذکر شده، با استفاده از مثال های آموزشی نسبت داده شده به هر گره، برای انتخاب بهترین صفت برای آزمایشی در آن گرهء درخت تکرار می شود. این روش جستجویی حریصانه را برای یک درخت تصمیم قابل قبول ارائه می دهد که در این الگوریتم، هیچ گاه برای در نظر گرفتن دوباره انتخاب های قبلی، به عقب برگشت نمی شود. این الگوریتم در یادگیری نمونه هایی با صفات فاقد مقدار مشکل داشته و غیرافزایشی و ارزان می باشد.
الگوریتم id4-hat:
این الگوریتم تغییر یافته الگوریتم id4 است؛ به شکلی که اگر درخت موجود نتواند نمونه جدید را به شکل صحیح دسته بندی کند این الگوریتم درخت را دوباره می سازد. اگر درخت نتواند دوباره ساخته شود بنابراین بهترین درخت نخواهد بود. در این حالت نتیجه با درخت نهایی تولید شده توسط ID3 متفاوت خواهد بود. هر دوی این الگوریتم ها وقتی بی نظمی صفر است یا تعداد خروجی های تصمیم را نگه می دارند و وقتی تمام … بجز یکی صفر است آن را متوقف می کنند.
الگوریتم id5:
یک الگوریتم افزایشی بهبود یافته است که توسط Utgoff توسعه یافته و همانند الگوریتم ID۴ شروع می شود. وقتی یک نمونه جدید اضافه می شود، اگر توسط درخت موجود به شکل صحیح دسته بندی نشود بهترین صفت بعدی را با استفاده از نفع اطلاعات برای دسته بندی این مثال اضافه می کند (در غیر این صورت درخت موجود را حفظ می کند.). در هر مرحله، اگر برای تمام نمونه هایی که تا این مرحله دیده شده اند، صفت پایین تر به نسبت صفت بالاتر بی نظمی شرطی کوچکتری داشته باشد درخت را با انجام تقسیم، معکوس کردن، ادغام و ساده سازی دوباره می سازد.
الگوریتم id5-hat:
در الگوریتم ID5 هرگاه که یک نمونه آموزشی اضافه می شود، بی نظمی های شرطی دوباره کنترل می شوند و در صورت لزوم ساختار درخت تغییر می یابد). این الگوریتم مشابه الگوریتم ID5 می باشد جز اینکه بی نظمی های شرطی فقط زمانی دوباره در نظر گرفته می شوند که درخت قادر به دسته بندی صحیح یک نمونه جدید نباشد.
الگوریتم c4.5:
نسل بعدی الگوریتم ID3 است و از نوعی از قانون هرس بعدی استفاده می کند. همچنین قادر است صفات گسسته، صفات فاقد مقدار و داده های نویزی را استفاده کند. این الگوریتم بهترین صفت را با استفاده از معیار بی نظمی انتخاب می کند و به دلیل استفاده از عامل GainRatio قادر به بکارگیری صفات با مقادیر بسیار زیاد می باشد. حتی اگر هیچ خطایی در داده های آموزشی وجود نداشته باشد هرس انجام می شود که باعث می شود درخت عام تر شده و کمتر به مجموعه آموزشی وابسته شود. هرس در این الگوریتم نسبتا پیچیده و بر پایه توزیع دوجمله ای و به شکل بازگشتی به برگ های درخت است. وقتی هرس یک شاخه متوقف می شود به سمت بالا ادامه نمی یابد. برای ممانعت از داشتن برگ هایی با یک نمونهء آزمایشی، جداسازی بیشتر روی دسته هایی که در حال حاضر به دو عنصر کاهش یافته اند انجام نمی شود. هرس فقط زمانی انجام می شود که تعداد پیش بینی شدهء خطاها افزایش نیابد. این الگوریتم، با در نظر گرفتن بی نظمی های هریک از آنها برای هر موردی که برای آنها داده داده شده است یک صفت را انتخاب می کند. بعد از انتخب بهترین صفت، موارد صفات فاقد مقدار با مقادیری از صفت در بخشی از مواردی که داده فراهم است تخصیص می یابند و الگوریتم ادامه می یابد.
الگوریتم cart:
روش عملکرد این الگوریتم surrogate splitting نام دارد. این الگوریتم شامل یک متد بازگشتی است. الگوریتم cart در هر مرحله رکورد های آموزشی را به دو زیر مجموعه تقسیم می کند. به طوریکه رکوردهای هر زیر مجموعه نسبت به زیر مجموعه های قبلی همگن تر باشد. این تقسیم شدنها به دفعات انجام می شود تا شرایط تو قف برقرار شود. در cart بهترین شکست با تعیین مقدار پارامتر ناخالصی تعیین می شود. اگر بهترین شکست برای یک شاخه ناخالصی را از حد تعریف شده کمتر کند آن انشعاب ساخته نمی شود مفهوم ناخالصی در اینجا به میزان شباهت مقدار فیلد هدف قرار بگیرد آن گره خالص نامیده می شود قابل توجه است که در الگوریتم cart یک فیلد پیشگو ممکن است به دفعات در سطوح مختلف درخت تصمیم گیری بکار گرفته شود.
الگوریتم C5.0:
یکی از الگوریتم های درختان تصمیم گیری می باشد. الگوریتم C5.0 یک نوع درخت تصمیم گیری تک متغیره و بهبود یافته الگوریتم C4.5 است که توسط محقق استرالیایی J.ross quinlan در سال 1993 طراحی شد. این الگوریتم مشابه با cart ابتدا درختی تقریبا پر ایجاد می کند ولی استراتژی هرس آن کاملا متفاوت است. این الگوریتم کلاسه بندی را با تقسیم کردن داده ها به زیر مجموعه هایی که شامل رکورد های همگن تر از والد خود هستند انجام می دهد. در C5.0 تقسیم کردن نمونه ها براساس فیلدی که بیشترین بهره اطلاعات را دارد صورت می گیرد.
شرح پروژه:
در این پروژه تشخیص بیماری قلبی با استفاده از تکنیک های داده کاوی و طبقه بندهای ماشین بردار پشتیبان، درخت تصمیم، بیز ساده، جنگل تصادفی، و رگرسیون لجستیک، بر روی مجموعه داده کلیولند Cleveland از UCI در نرم افزار پایتون(PHYHON) انجام شده است. به منظور انجام پیاده سازی، 80 درصد از داده ها جهت آموزش و 20 درصد داده ها برای تست مدل به کارگرفته شده است.
پایگاه داده :
برای پیاده سازی مدل پیشنهادی در این پروژه از نرم افزار پایتون(PYTHON) استفاده شده است. سپس مدل پیاده سازی شده با استفاده از داده های موجود در پایگاه داده UCI مورد آزمایش قرار گرفته است. در این آزمایشات، عملکرد مدل پیشنهادی از زوایای مختلف مورد ارزیابی قرار گرفته و نتایج حاصل تفسیر شده است. نتایج آزمایشات نشان می دهد که مدل پیشنهادی در تشخیص بیماری قلبی از دقت مناسبی برخوردار بوده و می تواند به عنوان یک ابزار برای تشخیص بیماری قلبی بر اساس اطلاعات پزشکی افراد مورد استفاده قرار گیرد. پایگاه داده داده های مورد استفاده در این تحقیق از طریق UCI جمع آوری شده است.
این پایگاه داده از طریق یکی از مراکز درمانی Cleveland جمع آوری شده و شامل اطلاعات پزشکی ۲۷۰ شخص می باشد. لیست اطلاعات موجود در پایگاه داده در جدول زیر نمایش داده شده است. مجموعه داده Cleveland توسط ربرت دترانو در مرکز پزشکی .V.A جمع آوری شده است . این مجموعه داده یکی از مجموعه داده های مشهور UCI بوده و در بسیاری از پژوهش ها مورد استفاده واقع شده است. تمام پژوهش های منتشر شده که روی این مجموعه داده کار نموده اند، تنها از یک زیر مجموعه ۱4 تایی از ویژگی ها، از بین76 ویژگی موجود در این مجموعه داده، استفاده نموده اند. 54% از نمونه های موجود در این مجموعه داده عضو کلاس سالم و46 ٪، عضو کلاس بیمار می باشند.
جدول مشخصات کلی پایگاه داده Cleveland.
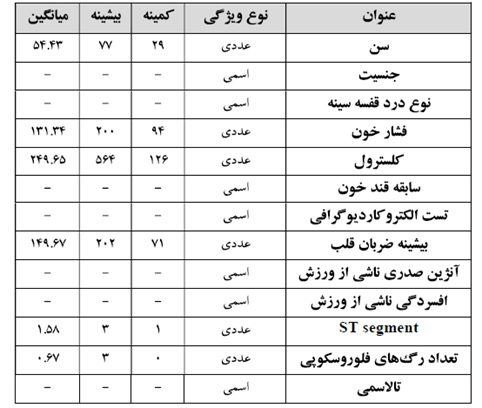
این پایگاه داده دارای ۱۳ ویژگی ورودی در زمینه اطلاعات جسمی بیماران بوده و فیلد خروجی پایگاه داده نشان دهنده وجود یا عدم وجود بیماری قلبی است. ویژگی سن افراد در این پایگاه داده بر حسب سن بوده و مقداری عددی دارد. جنسیت هر فرد بصورت مذکر و مونث مشخص شده که به ترتیب با اعداد ۱ و ۲ مشخص شده است. هر فرد ثبت شده در پایگاه داده دارای یک نوع درد قفسه سینه می باشد. این ویژگی بصورت اسمی در نظر گرفته شده و هر بیمار ممکن است یکی از چهار نوع درد قفسه سینه را داشته باشد. فشار خون افراد نیز بصورت عددی در پایگاه داده ثبت شده است. میزان کلسترول هر فرد از طریق آزمایش ادرار تعیین شده و بر حسب در پایگاه داده ثبت شده است. همچنین سابقه قند خون افراد بصورت اسمی در پایگاه داده ذخیره شده است؛ بطوری که اگر قند خون هر فرد بیشتر ازmg/dl 120 باشد، مقدار Yes و در غیر اینصورت مقدار No برای این خصوصیت فرد در نظر گرفته می شود. برای نتیجة تست الکتروکاردیوگرافی افراد یکی از اعداد0، 1 یا دو ذخیره می شود. ماکزیمم ضربان قلب افراد در تست ورزش برای هر فرد بصورت عددی که نشان دهنده تعداد ضربان در دقیقه است ذخیره می شود. در صورت وجود آنژین صدری ناشی از ورزش برای هر فرد عدد ۱ و در غیراینصورت عدد صفر در پایگاه داده ذخیره شده است. برای هر فرد که به افسردگی ناشی از ورزش مبتلا باشد در فیلد مربوطه عدد یک ذخیره خواهد شد و در غیر اینصورت این فیلد مقدار صفر را خواهد داشت. ویژگی تعداد رگ های فلوروسکوپی برای هر فرد بصورت یک عدد طبیعی بین صفر تا سه ذخیره می شود. در صورتی که هر فرد به تالاسمی مبتلا باشد، برای فیلد مربوط به این ویژگی مقدار Yes و برای افرادی که به این بیماری مبتلا نیستند مقدار No ذخیره شده است.
ماتریس کانفیوژن(confusion matrix):
در روش های دسته بندی، معمولاً نتیجه کار یک دسته بند روی یک مجموعه ی داده ای شامل c کلاس، در قالب یک ماتریس به نام ماتریس کانفیوژن بیان می شود. این ماتریس یک ماتریس مربعی با ابعاد cxc می باشد. سطرهای ماتریس نتیجه واقعی و ستون های آن نتیجه پیش بینی دسته بند را نشان می دهد. درایه سطر i و ستون j از این ماتریس، تعداد نمونه های کلاس i را که توسط دسته بند، کلاسj تشخیص داده شده را نشان می دهد. بدیهی است که قطر اصلی این ماتریس شامل تعداد نمونه هایی است که به درستی پوشش داده شده اند . ماتریس نشان داده شده در جدول زیر برای مجموعه های داده ای دو کلاسی بکار می رود. در مجموعه های دو کلاسی، معمولا کلاس ها به صورت مثبت(P)/ منفی (N)، یا نرمال/غیرنرمال یا 0/1 نام گذاری می شوند.
جدول ماتریس کانفیوژن دوبعدی.
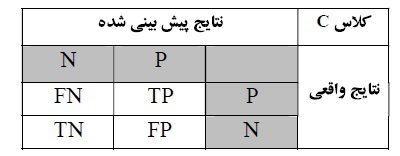
TP: تعداد نمونه هایی که دسته بند، آنها را جزء کلاس C تشخیص داده است و این تشخیص با نتیجه واقعی آن یکسان می باشد.
FN: تعداد نمونه هایی که دسته بند، آنها را جزء کلاس C تشخیص نداده است اما این نمونه ها متعلق به کلاس C می باشند.
FP: تعداد نمونه هایی که دسته بند، آنها را جزء کلاس C تشخیص داده است اما این تشخیص با نتیجه واقعی آن یکسان نمی باشد.
TN: تعداد نمونه هایی که دسته بند، آنها را جزء کلاس C تشخیص نداده است و نمونه ها متعلق به کلاس C نمی باشند.
کارایی یا دقت(Accuracy) یک دسته بند برابر است با درصد نمونه هایی که به درستی دسته بندی نموده است. براساس اطلاعات موجود در جدول فوق دقت دسته بند از رابطه ی زیر به دست می آید.
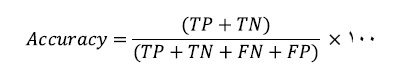
نرخ صحت(precision) نیز، بررسی می کند که از تعداد نمونه های درست دسته بندی شده، چه تعداد به دسته مثبت تعلق دارند.
نرخ یادآوری(recall) نیز بیان می کند که از تعداد نمونه های مثبت، چه تعداد به درستی دسته بندی شده اند.

نرخ سنجش-F (f-measure) یک مصالحه است بین این دو معیار و در واقع یک میانگین هم سازه از نرخ یادآوری می باشد. برای محاسبه نرخ سنجش-F از رابطه زیر استفاده می شود.

دو معیار دیگر نیز در مسائل پزشکی بسیار مورد توجه قرار می گیرند که عبارتند از: حساسیت(sensitivity) و اختصاصی بودن(specificity). معیار حساسیت با نرخ صحت یکسان است.
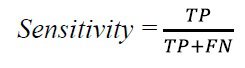
اختصاصی بودن نیز بیان می کند که از تعداد نمونه های منفی، چه تعداد به درستی دسته بندی شده اند و از رابطه زیر به دست می آید.
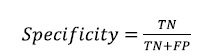
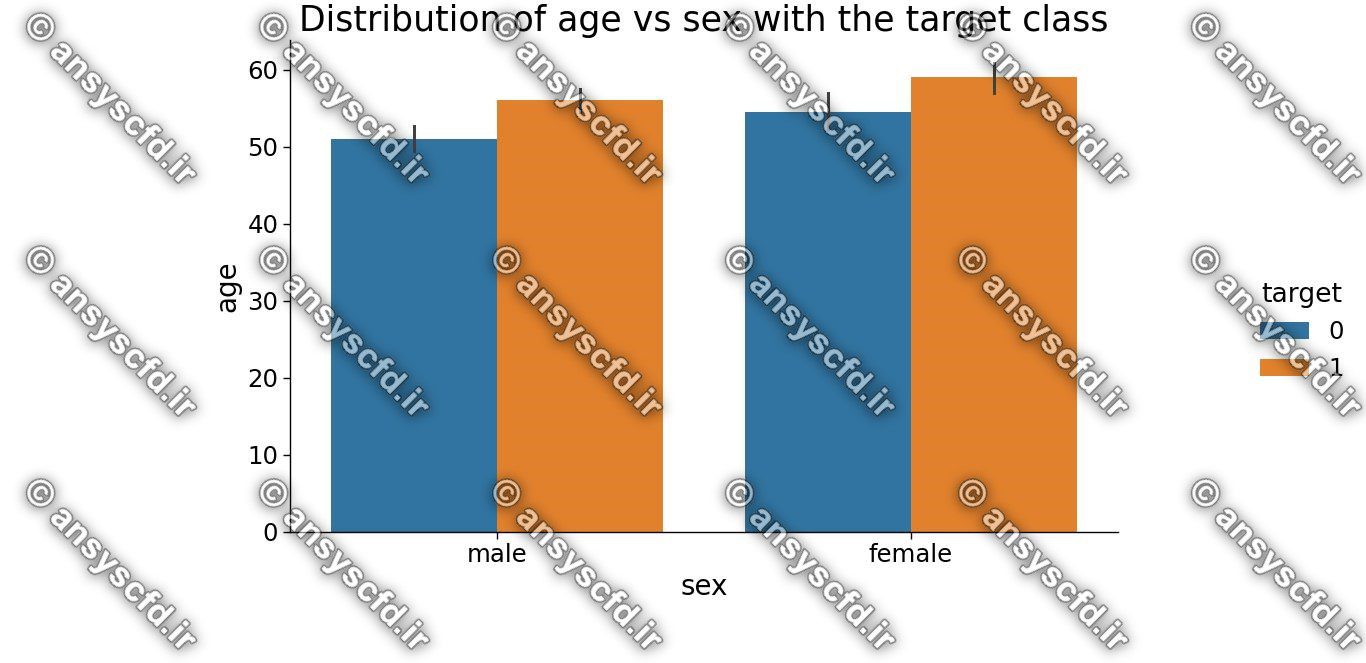
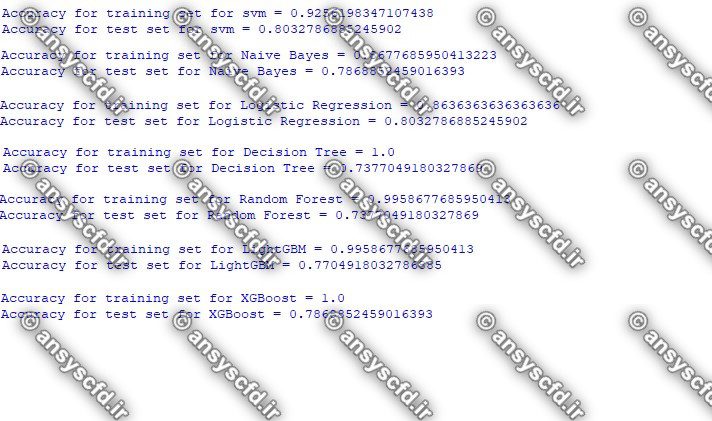
نمونه نتایج: