توضیحات
پروژه پایتون تشخیص اعداد و ارقام دستنویس فارسی با شبکه عصبی پرسپترون چندلایه(MLP) در پایگاه داده هدی
موضوع روش های تشخیص دست خط موضوعی است که در معرفی اولیه و دیده شدن عنوان آن، هر فردی، حتی اگر این فرد تحصیلات ویژه ای جهت شناخت اولیه این موضوع هم نداشته باشد، می تواند یک تداعی ذهنی و یک پیش زمینه قبل از ارائه آن در ذهن خود در رابطه با این عنوان و موضوع پیدا کرده و در شرایطی که این خصوصیت را به همراه دارد، موضوعی پر محتوا که جای بحث و پیش برد در همه بخشها و زیر شاخه ها در آن موجود می باشد را در خود حس می کند.
تعدادی از کاربردهای کلی تشخیص خودکار یک متن از تصویر بر گرفته از روی متن:
1-جستجو برای پیداکردن عبارتی خاص در یک مجموعه نوشته بزرگ
2-تنظیم و طبقه بندی نامه های پستی.
۳-پردازش های دلخواه بر روی متن تشخیص داده شده و چاپ متن دست نوشته با معیارهای دلخواه.
تشخیص دست خط
بیشترین مسائل دشوار در زمینه تشخیص کاراکتر ها (OCR) مربوط به تشخیص دستخط شکسته بدون قید می باشد. ابزار های کنونی هنوز به آن میزان از شایستگی و قابلیت اطمینان نرسیده اند تا توانایی مدل کردن تشخیص تنوع زیادی از دست خط افراد مختلف را داشته باشند. تشابه اشکال کاراکتر های مجزا، روی هم افتادگی ها، اتصالات داخلی در کاراکتر های مجاور یکدیگر باعث پیچیده شدن این موضوع شده است. به اضافه، مشاهده شده در هنگام جداسازی، کاراکتر ها اغلب دچار ابهام شده و جهت کاهش خطاهای دسته بندی نیاز به اطلاعات متنی داریم.
شناسایی دست خط نیازمند ابزارها و تکنیک های متعدد می باشد تا در شناسایی عبارات مجتمع شده از کاراکترها و همچنین موارد ابهام بوجود آمده در آنها از نظر برداشت های ادراک شده عادی راجع به اشکال و نمایش عمومی کاراکتر ها، کلمات، لغات و عبارات به درستی عمل کند.
شبکه های عصبی ابزار مکمل جهت حل پارهای از این مشکلات می باشند. شبکه های عصبی به صورت شبکه های غیرخطی و به هم متصل شده هستند، که جهت پردازش و تحلیل اطلاعات مبهم و مواردی که ابهام بر انگیز می باشد، به منظور تصمیم گیری های مرزی حساس، به کار می روند.
تشخیص ارقام دستنویس فارسی:
از تشخیص ارقام دستنویس فارسی در اکثر مجموعه هایی که با جمع آوری عمومی اطلاعات رقمی سر و کار دارند می توان استفاده کرد مانند خواندن مبالغ چک ها و ارقام کدپستی و …بازشناسی ارقام و حروف دست نویس فارسی، موضوعی است که سالها است روی آن کار می شود؛ چه در حوزه تحقیقات دانشگاهی و چه در حوزه های تجاری و کاربردی. مقالات و پایان نامه های متعددی در این زمینه ها ارائه شده است و البته کارهای صنعتی زیادی هم صورت گرفته است.
از مهمترین کاربردهای شناسایی ارقام و حروف دست نویس، پردازش برگه های ورود اطلاعات است. مثلا برگه های بانکی، برگه های ثبت نام در مؤسسات مختلف، برگه های پاسخنامه آزمون های سراسری و المپیادها یا برگه های دریافت وام! در اکثر این برگه ها، اطلاعات دست نویس مهم مانند نام و نام خانوادگی و شماره دانشجویی با کدملی و امثال این ها در فیلدهای مخصوصی وارد میشوند که بعداً پردازش آنها آسانتر صورت گیرد. البته ناگفته پیدا است که در بسیاری از سازمانهای ما هنوز پردازش خودکار فرم صورت نمیگیرد و همچنان کاربر انسانی است که اطلاعات را میخواند و وارد کامپیوتر میکند و اگر بدانیم که سالانه چند صد میلیون و یا شاید چندین میلیارد فرم توسط کاربر انسانی داده آمایی می شود، به اهمیت تشخیص ارقام و حروف دستنویس پی خواهیم برد.
برای طراحی دستگاههای نویسه خوان، مباحث مختلفی باید مورد بررسی قرار میگیرد. از جمله مباحث مطرح در طراحی این دستگاه های بازشناسی نوری حروف، بازشناسی قلم، بازشناسی زبان، اندازه گیری میزان چرخش صفحه، تحلیل پیکربندی اسناد، روشهای استخراج ویژگی، سیستم طبقه بندی، روشهای قطعه بندی کلمات و … هستند. از بین این مباحث، انتخاب روش استخراج ویژگی به عنوان مهمترین عامل در بازشناسی الگو مطرح است که جای کار زیادی دارد.
بازشناسی ارقام و کلمات دستنویس یکی از موضوعات مطرح در تشخیص الگو است و کاربردهای فراوانی دارد مانند شناسایی مبلغ چک، خواندن، شناسایی و دسته بندی کدپستی نامه ها و شناسایی متون دست نوشته. معمولاً روش هایی که برای شناسایی دستنوشته های انگلیسی بکار می روند برای دستنوشته های فارسی کاربردی ندارند و دلیل آن ویژگی های نوشتاری خط فارسی است، مانند پیوستگی حروف و زیرکلمات، اشکال متفاوت یک حرف، همپوشانی بین حروف، نقطه دار بودن حروف، اندازه متفاوت حروف و همچنین عدم سرمایه گذاری کافی و فقدان پایگاه داده ها و لغت نامه های استاندارد و جامع برای متون فارسی و عربی.
در چند دهه گذشته مسأله بازشناسی الگوهای نوشتاری شامل حروف، ارقام و سایر نمادهای متداول در اسناد مکتوب شده به زبان های مختلف، توسط گروههای مختلفی از محققین مورد مطالعه و بررسی قرار گرفته است. نتیجه این تحقیقات منجر به پیدایش مجموعه ای از روشهای سریع و تا حد زیادی مطمئن موسوم به OCR به منظور واردنمودن اطلاعات موجود در اسناد، مدارک، کتاب ها و سایر مکتوبات چاپی یا تایپ شده و حتی دستنویس کامپیوتر شده است. مسئله بازشناسی حروف الفبای فارسی سابقه ای نه چندان طولانی به همراه دارد. نخستین گزارش های رسمی منتشرشده از تلاش های انجام گرفته در این راه، مربوط به سالیان نخست دهه ۱۹۸۰ میلادی است.
به رغم فراگیری نسبی کاربرد الفبای فارسی در میان ملل مختلف قاره آسیا، بررسی های انجام شده در خصوص یافتن روش هایی برای بازشناسی حروف این الفبا بسیار محدود بوده است. به واسطه وجود تفاوت های اساسی بین نحوه نگارش کلمات فارسی و کلمات لاتین نظیر چسبیده بودن حروف سازنده یک کلمه به یکدیگر و تغییر شکل حروف بر اساس موقعیت نسبی قرار گیری آن در یک کلمه فارسی، امکان اعمال مستقیم روشهای متداول در بازشناسی حروف انگلیسی به منظور شناسایی حروف تشکیل دهنده کلمات فارسی وجود ندارد.
اکثر کارهای انجام شده در زمینه «OCR» در رابطه با متون لاتین، چینی و ژاپنی بوده است. نرم افزارهای تجاری «OCR» لاتین در سال های اخیر پیشرفت کیفی قابل ملاحظه ای داشته اند. اما «OCR» فارسی با وجود حجم نسبتا وسیع تحقیقات دانشگاهی و نیاز شدید بازار تجاری به آن، هنوز هم از جایگاه مورد نظر فاصله بسیاری دارد و تاکنون هیچ سیستم «OCR» کارآمدی که از نظر دقت و کیفیت محیط نرم افزاری، قابل مقایسه با سیستم های «OCR » لاتین باشد، عرضه نگردیده است. درنتیجه ضرورت انجام تحقیقات بیشتر در زمینه متون فارسی و عربی کاملا احساس می شود.
یادگیری عمیق
الگوریتم های یادگیری عمیق از الگوریتم های یادگیری ماشین هستند. اخیرا الگوریتم های یادگیری عمیق زیادی برای حل مسائل هوش مصنوعی سنتی ارائه شده اند. طی سالهای اخیر یادگیری عمیق در حوزه بینایی ماشین بصورت گسترده مورد مطالعه قرار گرفته است و به همین دلیل تعداد زیادی از روش های مرتبط با آن بوجود آمده است. این روش ها را بر اساس روش پایه ای که از آن مشتق شده اند می توان به ۴ دسته مختلف تقسیم کرد که عبارتند از:
Convolutional neural networks
Restricted Boltzmann Machines :RBMS
Autoencoders
Sparse Coding
شبکه عصبی کانولوشن (CNN)
الگوریتم های یادگیری عمیق زیرمجموعه ای از الگوریتم های یادگیری ماشین هستند، اخيرا الگوریتم های یادگیری عمیق زیادی برای حل مسائل هوش مصنوعی سنتی ارائه شده اند. شبکه های عصبی کانولوشن تاحد بسیار زیادی شبیه شبکه های عصبی مصنوعی هستند. این نوع شبکه ها متشکل از نورون هایی با وزن ها و بایاس های قابل یادگیری(تنظیم) هستند. هر نورون تعدادی ورودی دریافت کرده و سپس حاصل ضرب وزن ها در ورودی ها را محاسبه کرده و در انتها با استفاده از یک تابع تبديل(فعال سازی) غیرخطی نتیجه ای را ارائه می دهد. كل شبکه همچنان یک تابع امتیاز مشتق پذیر را ارائه میکند، که در یک طرف آن پیکسل های خام تصویر ورودی و در طرف دیگر آن امتیازات مربوط به هر دسته قرار دارد. این نوع شبکه ها هنوز یک تابع هزينه مثل( SVM , Softmax) ، در لایه آخر(تماما مرتبط) دارند و تمامی نکات مطرحی در مورد شبکه های عصبی معمولی در اینجا هم صادق است.
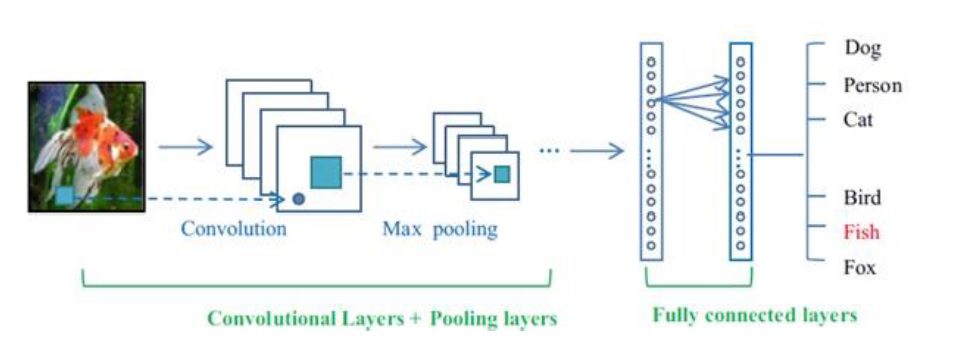
شبکه های عصبی كانولوشن یکی از مهم ترین روش های یادگیری عمیق هستند که در آنها چندین لایه با روشی قدرتمند آموزش می بینند، این روش بسیار کارآمد بوده و یکی از رایجترین روشها در کاربردهای مختلف بینایی کامپیوتر است. در هر شبکه عصبی کانولوشن دو مرحله برای آموزش وجود دارد. مرحله پیش خور و مرحله پس انتشار. در مرحله اول تصویر ورودی به شبکه تغذیه می شود و این عمل چیزی جز ضرب نقطه ای بین ورودی و پارامترهای هر نورون و در نهایت اعمال عمليات كانولوشن در هر لایه نیست.
سپس خروجی شبکه محاسبه می شود. در اینجا به منظور تنظیم پارامترهای شبکه و یا به عبارت دیگر همان آموزش شبکه، از نتیجه خروجی جهت محاسبه میزان خطای شبکه استفاده می شود. برای این کار خروجی شبکه را با استفاده از یک تابع خطا با پاسخ صحیح مقایسه کرده و اینطور میزان خطا محاسبه می شود. در مرحله بعدی براساس میزان خطای محاسبه شده مرحله پس انتشار آغاز می شود. در این مرحله گرادیان هر پارامتر باتوجه به قائده زنجیره ای محاسبه می شود و تمامی پارامترها باتوجه به تاثیری که بر خطای ایجاد شده در شبکه دارند تغییر پیدا میکنند. بعد از به روزآوری شدن پارامترها مرحله بعدی پیش خور شروع می شود. بعد از تکرار تعداد مناسبی از این مراحل آموزش شبکه پایان می یابد.
معماری شبکه های کانولوشن:
شبکه های عصبی یک ورودی دریافت می کنند(در قالب یک بردار) و سپس آن را از تعدادی لایه مخفی عبور می دهند. و درنهایت یک خروجی که نتیجه پردازش لایه های مخفی است در لایه خروجی شبکه ظاهر میشود. هر لایة مخفی از تعدادی نورون تشکیل شده که این نورون ها به تمام نورون های لایه قبل از خود متصل میشوند. نورون های هر لایه به صورت مستقل عمل کرده و هیچ ارتباطی با یکدیگر ندارند. آخرین لایه تماماً متصل به لايه خروجی معروف است و معمولاً نقش نمایش دهنده امتیاز هر دسته را ایفا میکند.
انواع لایه های شبکه های عصبی کانولوشن:
یک شبکه عصبی کائولوشن یک شبکه عصبی سلسله مراتبی است که لایه های کانولوشنی آن به صورت یک در میان با لایه های ادغام بوده و بعد از آنها تعدادی لایه تماماً متصل وجود دارد. بطور کلی، یک شبکه عصبی کانولوشن از سه لایه اصلی تشکیل می شود که عبارتند از: لایه کانولوشن، لایه ادغام و لایه تماماً متصل.
لایه های مختلف وظایف مختلفی را انجام می دهد.
در شکل زیر طرح کلی از یک معماری شبکه های عصبی کانولوشن برای دسته بندی تصاویر بصورت لایه به لایه نمایش داده شده است.
شکل طرح کلی از معماری شبکه عصبی کانولوشن.
لایه کانولوشن:
لایه کانولوشن هسته اصلی تشکیل دهنده شبکه عصبی کانولوشن است، و توده خروجی آن را میتوان به صورت یک توده سه بعدی از نورون ها تفسیر کرد. به زبان ساده تر یعنی اینکه خروجی این لایه یک توده سه بعدی است. برای درک بهتر این مسئله شبکه های عصبی معمولی را در نظر بگیرید. در شبکه های عصبی معمولی هر لایه چیزی جز لیستی از نورون ها نبوده که هر نورون خروجی خاص خود را تولید می کرد و نهایتاً یک لیست از خروجی ها که متناظر با هر نورون بود حاصل می شد. اما در شبکه عصبی كانولوشن به جای یک لیست ساده با یک لیست سه بعدی مواجه هستید که نورون ها در سه بعد آن مرتب شده اند. درنتیجه خروجی این مکعب نیز یک توده سه بعدی خواهد بود.
در این لایه ها، شبکه عصبی کانولوشن از هسته های مختلف برای کانولوشن کردن تصویر ورودی و همینطور نقشه ویژگی های میانی استفاده می کند و اینگونه نقشه ویژگی های مختلفی ایجاد می کند.
انجام عملیات کانولوشن سه فایده دارد:
1-مکانیزم اشتراک وزن در هر نقشه ویژگی باعث کاهش شدید تعداد پارامترها می شود.
2-اتصال محلی، ارتباط بین پیکسل های همسایه را یاد می گیرد.
3-باعث تغییرناپذیری و ثبات نسبت به تغییر مکان شیء می شود.
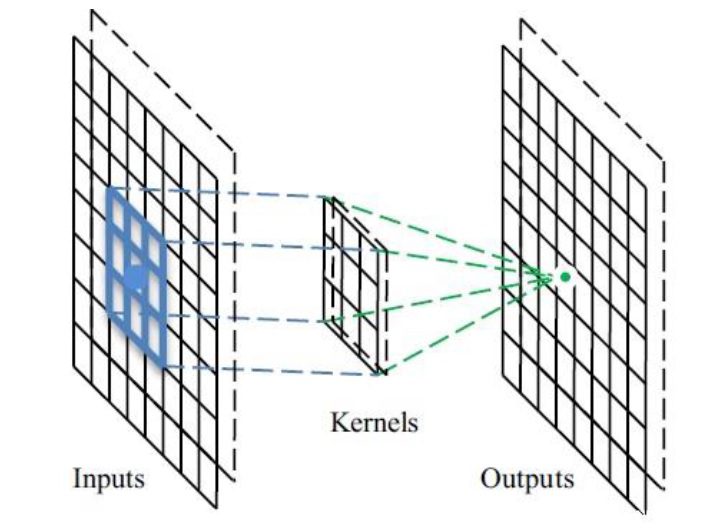
شکل زیر عملیات لایه كانولوشن را نشان می دهد.
شکل عملیات لایه کانولوشن.
لایه ادغام
یک لایة ادغام معمولاً بعد از یک لایة کانولوشنی قرار میگیرد و از آن برای کاهش اندازه نقشه ویژگی ها و پارامترهای شبکه می توان استفاده کرد. همانند لایه های کانولوشنی، لایه های ادغام بخاطر درنظرگرفتن پیکسل های همسایه در محاسبات خود، نسبت به تغییر مکان، بی تغییر(با ثبات) هستند.
پیاده سازی لایه ادغام با استفاده از تابع (max pooling) max و تابع(average pooling) average رایجترین پیاده سازی ها هستند. شکل عملیاتmax pooling را نشان می دهد.
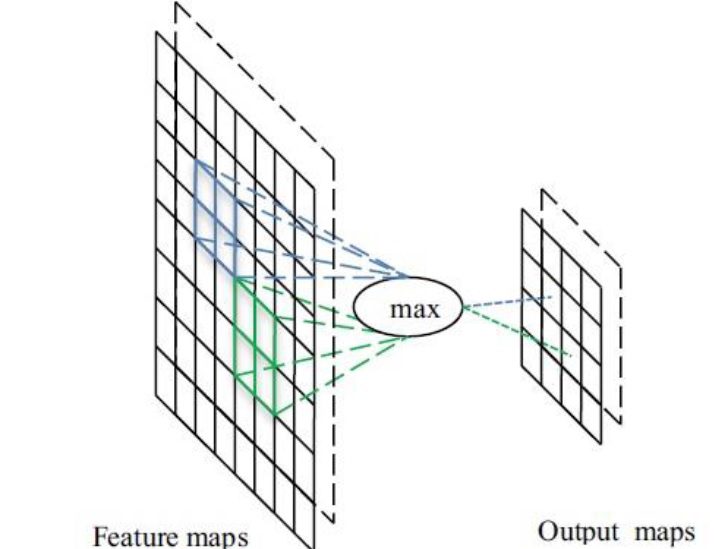
شکل عملیاتmax pooling
max pooling می تواند باعث همگرایی سریعتر، تعمیم بهتر و انتخاب ویژگی های نامتغیر بسیار عالی شود. طی سالهای اخیر پیاده سازی های سریع مختلفی از انواع مختلفی از شبکه های عصبی کانولوشن بر رویGPU انجام شده است که اکثر آنها از عملیاتmax pooling استفاده میکنند.
لایه تماما متصل:
بعد از آخرین لایة ادغام، لایه های تماماً متصل وجود دارند که نقشه ویژگی های دو بعدی را به بردار ویژگی یک بعدی جهت ادامه فرآیند نمایش ویژگی تبدیل می کند. شکل زیر عملیات لایه های تمام متصل را نشان میدهد.
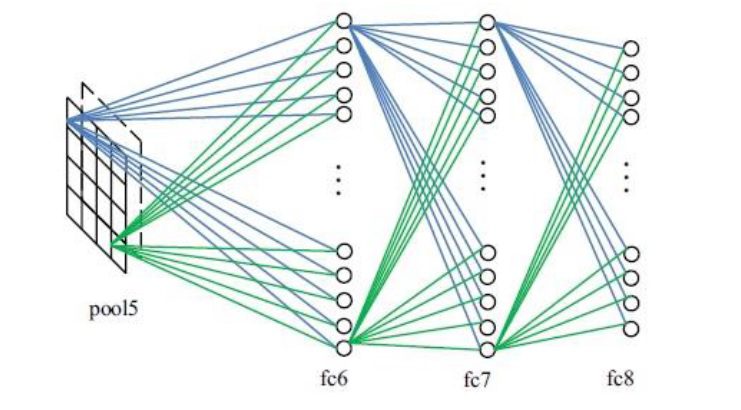
شکل عملیات لایه های تماما متصل.
لایه های تماما متصل همانند همتایان خود در شبکه های عصبی مصنوعی سنتی عمل می کنند و تقریبا 90% پارامترهای یک شبکه عصبی کائولوشن را شامل میشوند. لایة تماما متصل اجازه میدهد تا نتیجه شبکه را در قالب یک بردار با اندازه مشخص ارائه داده شود. میتوان از این بردار برای دسته بندی تصاویر استفاده شود و یا اینکه از آن جهت ادامه پردازش های بعدی بهره مند شد.
مشکل بزرگ این نوع لایه ها این است که دارای تعداد بسیار زیادی پارامتراند که نتیجة این امر هزینه پردازشی بسیار بالایی است که در زمان آموزش بایستی صرف شود. بنابراین یک روش که معمولاً به کار برده میشود و نتایج رضایت بخشی نیز دارد این است که با این لایه ها حذف شوند و یا تعداد اتصالات در این لایه ها توسط روشهایی کاهش یابد.
شبکه عصبی مصنوعی
شبکه های عصبی مصنوعی ساختار شبکه ای است که از تعدادی سلول به نام نورون مصنوعی تشکیل شده است و این نورون ها در داخل شبکه به یکدیگر متصل می باشند. هر سلول دارای ورودی و خروجی است و محاسبات جزئی را روی داده های ورودی خود انجام داده و به خروجی می فرستد، خروجی هر سلول نیز به ورودی سلولهای دیگر متصل است. شبکه های عصبی نوعی مدلسازی ساده انگارانه از سیستم های عصبی واقعی هستند که کاربرد فراوانی در حل مسائل مختلف در علوم دارند. حوزه کاربرد این شبکه ها آنچنان گسترده است که از کاربردهای طبقه بندی گرفته تا کاربردهایی نظیر درون یابی، تخمين، آشکارسازی و … را شامل می شود. شاید مهمترین مزیت این شبکه ها، توانایی وافر آنها در کنار سهولت استفاده از آنها باشد.
یکی از روش های کارآمد در حل مسائل پیچیده، شکستن آن به زیر مسأله های ساده تر است که هرکدام از این زیر بخش ها به نحو ساده تری قابل درک و توصیف باشند. در حقیقت یک شبکه، مجموعه ای از این ساختارهای ساده است که در کنار یکدیگر سیستم پیچیده نهایی را توصیف می کنند. شبکه ها انواع مختلفی دارند اما همگی آنها از دو مؤلفه تشکیل می شوند.
1- مجموعه ای از گره ها، هر گره در حقیقت واحد محاسباتی شبکه است که ورودی ها را گرفته و بر روی آن پردازش انجام می دهد تا خروجی بدست آید. پردازش انجام شده توسط گره میتواند از ساده ترین نوع پردازشها نظير جمع کردن ورودی ها تا پیچیده ترین محاسبات را شامل شود. در حالت خاص، یک گره میتواند خود، شامل یک شبکه دیگر باشد.
٢. اتصالات بین گره ها، این اتصالات نحوه گذر اطلاعات بین گره ها را مشخص میکند. در حالت کلی اتصالات میتوانند تک سویه (Unidirectional) باشند یا دوسویه(Bidirectional) .
تعامل بین گره ها از طریق این اتصالات سبب بروز یک رفتار کلی از سوی شبکه می گردد که چنین رفتاری به تنهایی در هیچیک از المان های شبکه دیده نمی شود. جامع بودن این رفتار کلی بر عملکرد موجود در هر گره سبب تبدیل شبکه به یک ابزار توانمند می شود. به عبارت دیگر، مجموعه ساده ای از المان ها وقتی در قالب یک شبکه باشند می توانند رفتاری از خود بروز دهند که هیچیک از آن المانها به تنهایی قادر به بروز چنین مشخصه ای نبود.
انواع مختلفی از شبکه ها وجود دارد. در این بین شبکه ای وجود دارد که گره را به عنوان یک نورون مصنوعی در نظر می گیرد. در اصطلاح، این چنین شبکه هایی را شبکه عصبی مصنوعی(ANN) می نامند. یک نورون مصنوعی در حقیقت مدلی محاسباتی است که از نورون های عصبی واقعی انسان، الهام گرفته است. نورونهای طبیعی، ورودی خود را از طریق سیناپس دریافت می کنند. این سیناپس ها بر روی دندریت ها یا غشاء عصب قرار دارند. در یک عصب واقعی، دندریت ها دامنه پالس های دریافتی را تغییر می دهند که نوع این تغيير در طول زمان یکسان نمی ماند و در اصطلاح، توسط عصب یاد گرفته می شود. اگر سیگنال دریافتی به حد کافی قوی باشد (از یک مقدار آستانه بیشتر شود)، عصب فعال شده و سیگنالی را در طول اکسون منتشر می کند. این سیگنال نیز به نوبه خود می تواند به یک سیناپس دیگر وارد شده و سایر اعصاب را تحریک کند.
به هنگام مدل کردن اعصاب، از پیچیدگی های آن ها صرف نظر می شود و تنها به مفاهیم پایه ای بها داده می شود، چرا که در غیر این صورت رویکرد مدلسازی بسیار دشوار خواهد شد. در یک نگاه ساده، مدل یکی عصب باید شامل ورودی هایی باشد که در نقش سیناپس انجام وظیفه کنند. این ورودی ها در وزن هایی ضرب می شوند تا قدرت سیگنال را تعيين كنند. نهایتاً یک عملگر ریاضی تصمیم گیری می کند که آیا نورون فعال شود یا خير و اگر جواب مثبت باشد، میزان خروجی را مشخص می سازد. بنابراین شبکه عصبی مصنوعی با استفاده از مدل ساده شده عصب واقعی به پردازش اطلاعات می پردازد. با توجه به این توضیحات، میتوان مدل ساده ای برای توصیف یک نورون(یک گره در شبکه عصبی مصنوعی) پیشنهاد کرد. جدای از ساده سازی های اعمال شده، تفاوت اصلی این مدل با واقعیت در این است که در شبکه واقعی، ورودی ها سیگنال های زمانی هستند حال آن که در این مدل، اعداد حقیقی ورودی اند.
هرچند نحوه مدل کردن نورون جزء اساسی ترین نکات کلیدی در کار آیی شبکه عصبی می باشد اما نحوه برقراری اتصالات و چیدمان(توپولوژی) شبکه نیز فاکتور بسیار مهم و اثرگذاری است. باید توجه داشت که توپولوژی مغز انسان آنقدر پیچیده است که نمیتوان از آن به عنوان مدلی برای اعمال به شبکه عصبی استفاده نمود، چرا که مدلی که ما استفاده می کنیم، یک مدل ساده شده است در حالی که چیدمان مغز از المان های بسیار زیادی استفاده می کند.
شبکه های عصبی را می توان با اغماض زیاد، مدلهای الکترونیکی از ساختار عصبی مغز انسان نامید. مکانیسم فراگیری و آموزش مغز اساساً بر تجربه استوار است. مدلهای الکترونیکی شبکه های عصبی طبیعی نیز براساس همین الگو بنا شده اند و روش برخورد چنین مدلهایی با مسائل، با روشهای محاسباتی که به طور معمول توسط سیستمهای کامپیوتری در پیش گرفته شده اند، تفاوت دارد. میدانیم که حتی ساده ترین مغزهای جانوری هم قادر به حل مسائلی هستند که اگر نگوییم کامپیوترهای امروزی از حل آنها عاجز هستند، حداقل در حل آنها دچار مشکل می شوند. به عنوان مثال، مسائل مختلف شناسایی الگو، نمونه ای از مواردی هستند که روش های معمول محاسباتی برای حل آنها به نتیجه مطلوب نمی رسند. در حالی که مغز ساده ترین جانواران به راحتی از عهده چنین مسائلی بر می آید. تحقیقات در اینزمینه نشان داده است که مغز، اطلاعات را همانند الگوها ذخیره می کند. فرآیند ذخیره سازی اطلاعات به صورت الگو و تجزیه و تحلیل آن الگو، اساس روش نوین محاسباتی را تشکیل می دهند. این حوزه از دانش محاسباتی به هیچ وجه از روشهای برنامه نویسی سنتی استفاده نمی کند و به جای آن از شبکه های بزرگی که به صورت موازی آرایش شده اند و تعلیمیافته اند، بهره می جوید.
یک شبکه عصبی مصنوعی ایده ای است برای پردازش اطلاعات که از سیستم عصبی زیستی الهام گرفته شده و مانند مغز به پردازش اطلاعات می پردازد. عنصر کلیدی این ایده، ساختار جدید سیستم پردازش اطلاعات است. این سیستم از شمار زیادی عناصر پردازشی فوق العاده به هم پیوسته تشکیل شده که برای حل یک مسئله با هم هماهنگ عمل می کند. ANN ها، نظیر انسانها، با مثال یاد می گیرند. یکANN برای انجام وظیفه ای مشخص، مانند شناسایی الگوها و دسته بندی اطلاعات، در طول یک پروسه یادگیری، تنظیم می شود. در سیستم های زیستییادگیری با تنظیماتی در اتصالات سیناپسی که بین اعصاب قرار دارد همراه است این روش ANN ها نیز است.
یک شبکه عصبی مصنوعی شامل تعداد زیادی از نورونهاست که براساس یک الگوی اتصال به هم پیوندیافته اند. نورونها معمولا به سه دسته تقسیم می شوند: نورونهای ورودی، که ورودی را برای پردازش دریافت می کنند. نورنهای خروجی که حاوی نتیجه پردازش هستند و نورونهای میانی که به نام نورونهای پنهان نامیده می شوند.
نورون های ورودی از طریق منابع خارجی فعال می شوند. هر نورون ورودی پس از فعال شدن مقدار فعال سازی خود را به نورون های پنهانی که به آنها متصل است می فرستند. هرکدام از نورون های پنهان با توجه به مقادیری که از نورون های همسایه خود دریافت می کند، فعال بودن خود را تعیین می کند و اگر فعال بشود مقدار فعال سازی خود را به نورون های خروجی یا به لایه دیگری از نورون های پنهان می فرستند و به طور پیوسته و همزمان تمام نورون ها به کار خود ادامه می دهد و به این ترتیب سیگنال های تولید شده توسط نورون های ورودی در تمام شبکه پخش می شوند تا وضعیت فعال بودن نورون های خروجی مشخص شود. الگوی فعال شدن یک شبکه توسط وزن بین نورون های آن مشخص می شود.
وزن می تواند مثبت یا منفی باشد. یک وزن منفی نشان دهنده عدم تمایل نورون مقصد نسبت به فعال شدن در صورت فعال بودن نورون مبدأ است. فعال بودن هر نور و توسط یک تابع ساده فعال سازی انجام می شوند. توابع فعال سازی مختلفی وجود دارند اما همگی بر یک پایه بنا شده اند. تابع تمام ورودی های نورون(اگر نورون مبدأ فعال باشد اندازه ورودی آن به نورون مقصد به اندازه وزن بین آن دو است.) را با هم جمع می کند. حاصل جمع معمولا کمی تغییر می یابد. مثلا به عددی بین۰ و 1 تبدیل می شود و سپس اگر این مجموع از عددی خاص بیشتر بود، نورون فعال می شود. شبکه ای که در بالا معرفی شد معروف به شبکه feed forward است. در این شبکه ورودی از لایه ورودی دریافت شده و سپس از یک یا چند لایه پنهان میگذرد تا به لایه خروجی برسد.
شبکه عصبی پرسپترون چندلایه(MLP)
یکی از ساده ترین و در عین حال کار آمدترین چیدمان های پیشنهادی برای استفاده در مدلسازی عصب های واقعی، شبکه پرسپترون چند لایه(Multi-layer perceptron) یا به اختصار MLP می باشد که از یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی تشکیل یافته است. در این ساختار، تمام نورون های یک لایه به تمام نورون های لایه بعد متصلند. این چیدمان اصطلاحاً یک شبکه با اتصالات کامل را تشکیل می دهد.
به طور کلی شبکه های عصبی مصنوعی از لحاظ یادگیری بر دو دسته اند: شبکه های وزن ثابت و شبکه های با وزن متغير(شبکه های یادگیرنده). خود شبکه های یادگیرنده نیز به دو دسته با ناظر (Supervised) و بدون ناظر (Unsupervised) تقسیم می شوند. در شبکه های با ناظر، در فاز آموزش از نمونه هایی استفاده میگردد که خروجی ایده آل متناظر با آنها از پیش دانسته است. به عبارت دیگر در این گونه شبکه های نمونه های داده ورودي، برچسب دارند. در شبکه های بدون ناظر، براساس یک معیار(مثلاً فاصله) و براساس نوعی رقابت، خروجی موردنظر در کلاس جداگانه قرار میگیرد. باتوجه به این که شبکة عصبی، مدل ساده شده اعصاب بدن است، درست به مانند آنها قابلیت یادگیری دارد. به عبارت دیگر، شبکه با استفاده از اطلاعاتی که از ورودی و توسط سرپرست خود دریافت میکند، قادر به فراگیری روند موجود در الگوها است. لذا به طور مشابه با انسان، روند یادگیری در شبکه عصبی نیز از مدلهای انسانی الهام گرفته است. بدین صورت که مثالهای بسیاری را به دفعات بایستی به شبکه ارائه نمود تا بتواند با تغيير وزن های شبکه، خروجی مورد نظر را دنبال کند.
بطور کلی می توان سیستم هایOCR را از لحاظ نحوه نگارش به دو گروه تقسیم کرد:
1-سیستم های بازشناسی متون چاپی
2- سیستم های بازشناسی متون دستنویس
متن های چاپی به متونی هستند که حروف آن شکل و فرمت ثابتی دارند و براساس یک الگوی از قبل تعیین شده نوشته میشوند. متون دستنویس، به متن هایی گفته میشود که توسط افراد مختلف نوشته میشود و شامل حروف گسسته و یا کلمات و متونی که توسط دست نگارش شده اند. بطورکلی نوشته های دستنویس شکل و فرمت نوشتاری متغیری دارند و از الگوی خاصی پیروی نمیکنند.
همچنین سیستم هایOCR را از لحاظ نوع الگوی ورودی به دو گروه اصلی سیستمهای برخط و برون خط تقسیم کرد:
در بازشناسی برخط یا بلادرنگ، حروف در همان زمان نگارش توسط سیستم تشخیص داده میشوند و توسط سخت افزار و الگوریتم خاصی کار میکنند. در شناسایی حروف و کاراکترها بصورت بلادرنگ عملیات شناسایی زمانی انجام میشود که کاربر در حال رسم حروف و یا کاراکترها میباشد.
جهت انجام این کار به یک صفحه الکترونیکی با دقت ۲۰۰ نقطه در اینچ و سرعت نمونه برداری۱۰۰ نقطه در ثانیه، نیاز است. همچنین این صفحه باید قادر به ارسال اطلاعات بصورت یک بعدی نیز باشد. دستگاه ورودی این سیستمها یک قلم نوری است. در این روش علاوه بر اطلاعات مربوط به موقعیت قلم، اطلاعات زمانی مربوط به مسیر قلم نیز در اختیار است. این اطلاعات معمولاً توسط یک صفحه رقومی کننده دریافت میشوند. در این روش میتوان از اطلاعات زمانی سرعت، شتاب، فشار و زمان برداشتن و گذاشتن قلم روی صفحه در بازشناسی استفاده کرد.
در بازشناسی برون خط، از تصویر دو بعدی متن ورودی استفاده میشود و عملیات شناسایی پس از چاپ یا نوشتن کامل متون انجام خواهد شد. در این روش به هیچ نوع وسیله نگارش خاصی نیاز نیست و تفسیر داده ها مستقل از فرآیند تولید آنها تنها براساس تصویر متن صورت می گیرد.
این روش به نحوه بازشناسی توسط انسان شباهت بیشتری دارد. در این پژوهش سیستم شناسایی از نوع برون خط میباشد. شکل زیر نمای کلی از قسمت های مختلف یک سیستمOCR کامل را نشان میدهد.
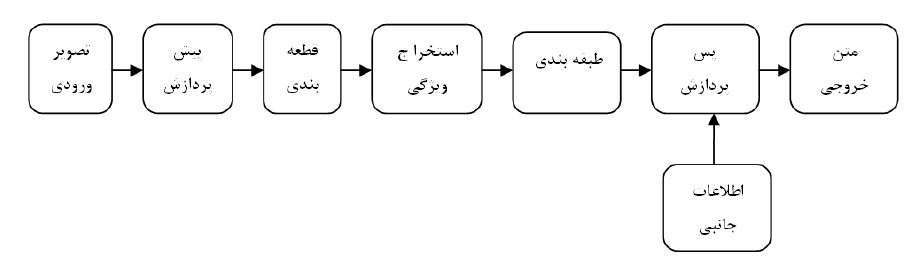
شکل بلوک دیاگرام کلی یک سیستم کامل شناسایی نوری متون.
پیش پردازش:
پیش پردازش، شامل کلیة عملیاتی است که روی سیگنال تصویری خام صورت میگیرد تا مراحل بعدی با سهولت بیشتری اجرا گردند. از جمله این عملیات میتوان به باینری کردن تصویر، حذف نویز و افزایش کیفیت تصویر، نرمال کردن داده ها، هموارسازی، نازک سازی ، تشخیص زبان و فونت کلمات و مانند اینها اشاره نمود.
قطعه بندی:
قطعه بندی غلط کاراکترها، عامل بسیاری از خطاهایOCR است میزان دقت یک الگوریتم قطعه بندی به سبک نگارش حروف، کیفیت دستگاه پرینت و نیز نسبت اندازه فونت به رزولوشن دستگاه اسکنر بستگی دارد. دو نوع قطعه بندی وجود دارد که شامل قطعه بندی بیرونی و قطعه بندی درونی می باشد.
استخراج ویژگی :
استخراج ویژگی انجام عملیاتی روی داده ها است تا ویژگی های شاخص و تعیین کننده آن ها مشخص شوند و هدف این است تا اطلاعات خام به شکل مفیدتری برای پردازش های بعدی در آیند. این بخش یکی از مشکل ترین و مهمترین مراحل سیستم نویسه خوان نوری است. آسان ترین راه برای توصیف یک حرف، استفاده از تصویر واقعی آن است.
این روش، از تکنیک تطابق قالبی استفاده میکند. روش دیگر، استخراج ویژگی های معین از حروف و صرفنظرکردن از ویژگی های جزئی مانند: ناحیه بندی، ممان ها، تقاطع و فاصله ها، مکان هندسی اساسی و تبدیلات و بسط های سری می باشد. همچنین با تحلیل ساختاری میتوان ویژگی هایی که ساختارهای توپولوژیکی و هندسی یک نماد را توصیف می کنند، استخراج نمود. با این ویژگی ها، تلاش میشود که ساختار فیزیکی حروف توصیف شوند.
طبقه بند:
این مرحله، آخرین مرحله پردازش در یک سیستم نویسه خوان نوری است. در این مرحله، هر حرف شناسایی می گردد و به کلاس حرفی مناسب ارجاع داده میشود. از متدهای مورد استفاده در این بخش میتوان به روشهای تئوری تصمیم گیری، روشهای ساختاری و شبکه های عصبی اشاره کرد. نوع طبقه بندی که در این تحقیق استفاد شد شبکه عصبی پرسپترون چندلایه می باشد.
بکارگیری اطلاعات جانبی (پس پردازش)
در این مرحله میتوان با استفاده از اطلاعات جانبی، نتایج حاصل از مرحله بازشناسی را بهبود بخشید. تا قبل از این قسمت، هیچگونه اطلاعات مفهومی در روند مراحل پردازش استفاده نشده بود. در مرحله پیش پردازش تصاویر، به دلیل عدم دسترسی به اطلاعات مفهومی، ممکن است برخی از اطلاعات مهم تصویر حذف گردد. فقدان اطلاعات معنایی در مرحلة قطعه بندی می تواند به نتایج بسیار بدی منجر شود چرا که خروجی این مرحله، تعیین کننده مرز الگوهای ورودی میباشد. بنابراین واضح است که درصورت فراهم شدن اطلاعات معناشناختی، دقت نتایج بازشناسی به نحو چشمگیری افزایش می یابد.
شبکه عصبی احتمالی(PNN)
شبکه عصبی احتمالی یا PNN یک ابزار طبقه بندی برجسته است که هرقالب ورودی را به تعدادی کلاس می نگارد و میتواند به تابعی عمومی برای تقریب زدن تبدیل شود. این شبکه تعریفی از یک الگوریتم احتمالی به نام تفکیک آنالیز هسته است که در آن عملیات ها به صورت شبکه چند لایه ای پیشرو با چهار لایه سازماندهی شده اند که عبارتند از :
- لایه ورودی
- لايه الگو
- لایه جمع بندی
- لایه خروجی.
این شبکه هنگامی مفیدترین و بیشترین کاربرد را داراست که رابطه بین خروجی و یا متغیر مستقل شبکه با پارامترهای ورودی شبکه غیرخطی باشد. در حقیقت شبکه PNNیک طرح درون یابی ریاضی است که برای اجرای خود از یک شبکه عصبی استفاده می کند. این موضوع خود یک مزیت برای شبکه PNN به حساب می آید چون می توان با مطالعه فرمول های ریاضی، رفتار این شبکه را بهتر از رفتار شبکه MLP بررسی کرد.
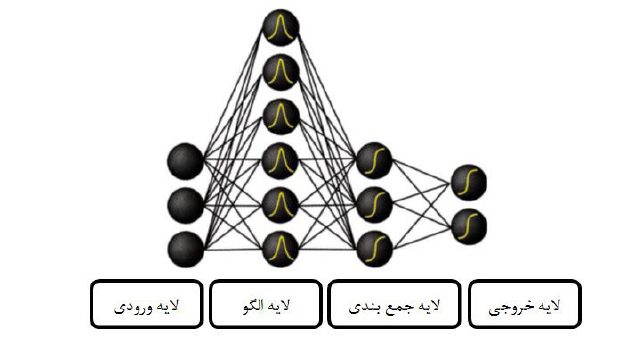
شکل ساختار یک شبکه عصبی احتمالی.
پایگاه داده:
به دلیل روند رو به گسترش تولید و استفاده از سیستم های مبتنی بر نویسه خوانی نوری(OCR)، اهمیت وجود بانک های اطلاعات تصاویر نوشتار فارسی بیش از پیش احساس می شود. این بانک های اطلاعاتی هم به منظور توسعه و آموزش الگوریتم های آموزش پذیر و هم به منظور ارزیابی سیستم های ساخته شده، استفاده می شوند. در طی این سال ها برای بهبود روند تحقیق و معیاری برای مقایسه روش ها، پایگاه های داده استانداری توسط برخی محققین ساخته شده است. در اینجا به برخی از این پایگاه های داده اشاره می شود.
پایگاه داده هدی:
مجموعه ارقام دستنویس هدی که اولین مجموعهی بزرگ ارقام دستنویس فارسی است، مشتمل بر 102353 نمونه دستنوشته سیاه سفید است. این مجموعه طی انجام یک پروژهی کارشناسی ارشد درباره بازشناسی فرمهای دستنویس تهیه شده است. داده های این مجموعه از حدود 12000 فرم ثبت نام آزمون سراسری کارشناسی ارشد سال 1384 و آزمون کاردانی پیوسته دانشگاه جامع علمی کاربردی سال 1383 استخراج شده است. خصوصیات این مجموعه داده به شرح زیر است:
درجه تفکیک نمونهها: ۲۰۰ نقطه بر اینچ
تعداد کل نمونهها: ۱۰۲۳۵۲ نمونه
تعداد نمونههای آموزش: ۶۰۰۰ نمونه از هر کلاس
تعداد نمونههای آزمایش: ۲۰۰۰ نمونه از هر کلاس
سایر نمونهها: ۲۲۳۵۲ نمونه

شکل نمونه هایی از پایگاه داده هدی
پایگاه داده IFHCDB
این پایگاه داده در دانشگاه امیرکبیر تهیه شده است. این پایگاه داده شامل ۵۲۳۸۰ کاراکتر و ۱۷۷4۰ رقم است. این نمونه ها به صورت خاکستری بوده و دقت آنها ۳۰۰ نقطه بر اینچ است. نمونه هایی از این پایگاه داده در شکل زیر نشان داده شده است.

شکل نمونه هایی از پایگاه داده IFHCDB
پایگاه داده CENPARMI
این پایگاه داده نیز به منظور انجام تحقیقات بر روی کاراکترهای برون خط فارسی تهیه شده است. این پایگاه داده شامل ۱۸۰۰۰ نمونه ارقام مجزا در ده کلاس است در شکل زیر نمونه هایی از این پایگاه داده در شکل زیر نشان داده شده است.
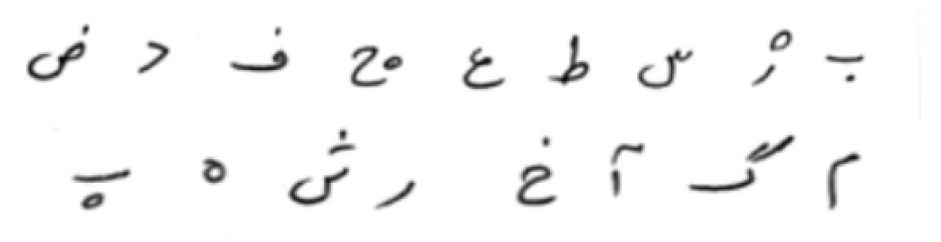
شكل نمونه هایی از پایگاه داده CENPARMI
پایگاه داده ICDAR2009
این پایگاه داده در ۱۲ کلاس و ۲۵۰۰ نمونه آموزش و ۲۰۰۰ نمونه آزمایش برای هرکلاس گردآوری شده است. نمونه هایی از این پایگاه داده در شکل زیر نشان داده شده است.
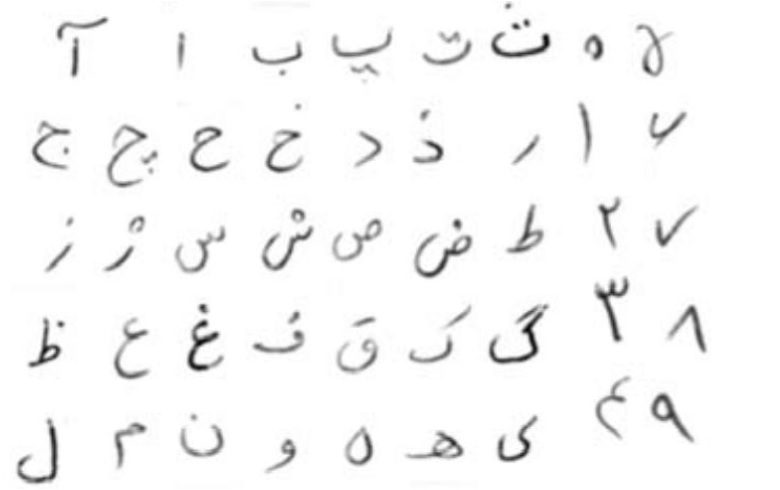
شکل نمونه هایی از پایگاه داده ICDAR2009
پایگاه داده حروف گسسته دست نویس فارسی
متن دست نویس گسسته همان نوشته هایی است که حروف آن جدا از هم و به صورت گسسته نوشته شده اند، مثل نام و نام خانوادگی که در فرم های آزمون ثبت نام به صورت هر حرف داخل یک کادر نوشته می شوند. بانک اطلاعاتی حروف گسسته دست نویس مشتمل بر ۱۰ میلیون و ۲۳۶ هزار و 40 نمونه تصویر است که حجم كل آن حدود ۱۲۰ گیگابایت می باشد. تصاویر موجود در این بانک در قالب BMP، با وضوح تصویر۳۰۰ نقطه در اینچ و به صورت خاکستری۲۵۹ سطحی عرضه شده اند. نمونه های از این پایگاه داده در شکل زیر نشان داده شده است.

شکل نمونه هایی از پایگاه داده حروف گسسته دست نویس فارسی
مجموعه داده هدی:
مجموعه ارقام دستنویس هدی که اولین مجموعهی بزرگ ارقام دستنویس فارسی است، مشتمل بر 102353 نمونه دست نوشته سیاه سفید است. این مجموعه طی انجام یک پروژهی کارشناسی ارشد درباره بازشناسی فرمهای دستنویس تهیه شده است. داده های این مجموعه از حدود 12000 فرم ثبت نام آزمون سراسری کارشناسی ارشد سال 1384 و آزمون کاردانی پیوستهی دانشگاه جامع علمی کاربردی سال 1383 استخراج شده است. خصوصیات این مجموعه داده به شرح زیر است:
درجه تفکیک نمونهها: ۲۰۰ نقطه بر اینچ
تعداد کل نمونهها: ۱۰۲۳۵۲ نمونه
تعداد نمونههای آموزش: ۶۰۰۰ نمونه از هر کلاس
تعداد نمونههای آزمایش: ۲۰۰۰ نمونه از هر کلاس
سایر نمونهها: ۲۲۳۵۲ نمونه
تعداد نمونه ها در هر كلاس:
| رقم ٠ | رقم ١ | رقم ٢ | رقم ٣ | رقم ٤ | رقم ٥ | رقم ٦ | رقم ٧ | رقم ٨ | رقم ٩ |
| 10070 | 10330 | 9923 | 10334 | 10333 | 10110 | 10254 | 10363 | 10264 | 10371 |

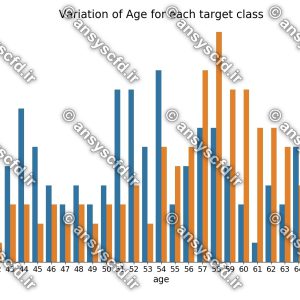
شکل نمونه هایی از دستخط های مختلف موجود در مجموعه ارقام دستنویس.

نمونه هایی از کیفیت های مختلف موجود در مجموعه ارقام دستنویس.
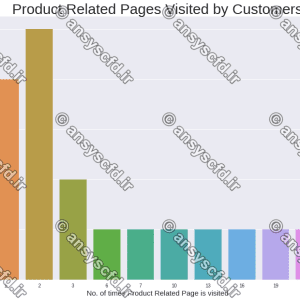
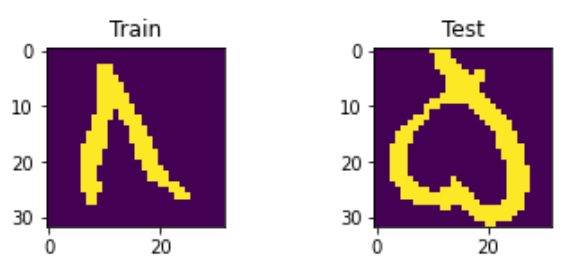
در این پروژه از شبکه عصبی پرسپترون چندلایه(MLP) که نوعی شبکه عصبی مصنوعی(ANN) است برای مجموعه داده هدی استفاده شده است. یک نمونه از این دیتاست به صورت زیر نشان داده شده است.
طراحی شبکه عصبی MLP با استفاده از نرم افزار پایتون(کراس) صورت گرفته است.
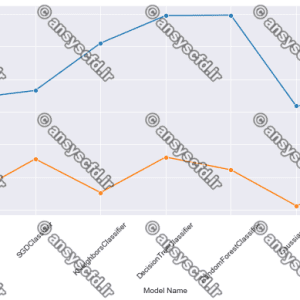
نتایج ارزیابی با معیارهای دقت، فراخوانی، امتیاز F1، و صحت به صورت زیر نشان داده می شود.